지난 포스팅에서는 호텔 리뷰 분석에 어떤 데이터가 필요한지를 소개했었다.
[Data Analysis/개인 프로젝트] - [호텔 리뷰 분석] 1. 어떤 데이터를 어떻게 분석할 것인가?
[호텔 리뷰 분석] 1. 어떤 데이터를 어떻게 분석할 것인가?
호텔 리뷰를 분석하는 프로젝트를 진행해보려 한다. 분석할 리뷰는, 트립어드바이저(링크)에 등록된 그랜드하얏트 제주 호텔의 리뷰. 따로 데이터를 제공하지 않으니, 스크래핑으로 분석에 필
k-wien1589.tistory.com
이제 본격적으로 진행해보자.
Process 1.
리뷰가 있는 메인 페이지의 url에 접근해서
1) 총 리뷰 개수 구하고
2) 총 페이지의 수를 구한다.
* 구글 코랩 환경에서 진행한다.
스크래핑에 필요한 라이브러리를 import 한다.
필요한 건 requests(링크)와 BeauitifulSoup(링크)
** requests와 BeautifulSoup에 대해 잘 모른다면 위의 링크에 들어가서 한번씩 읽어보도록 하자.

우리가 가져올 데이터가 있는 메인 페이지의 url은 이렇다.
들어가보면, 아래 사진처럼 리뷰가 모여있는 섹션이 있다.
페이지 넘버가 보인다. 여러 페이지가 있는 모양이다. 페이지 하나당 리뷰는 5개씩 있다.
페이지를 하나하나 넘기다 보면, 반복되는 url의 패턴을 발견할 수 있다.
페이지 번호만 가지고 해당 번호의 페이지 url에 접근하고 싶다.
그러기 위해 우선 메인 페이지 url을 변수로 만들어 둔다.

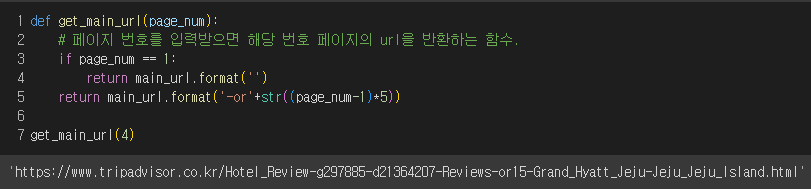
그리고 나서, 아래와 같은 함수를 작성해 주었다.
url을 잘 반환하는 것을 볼 수 있다.
이제 requests 라이브러리로 url에 접근해보자.
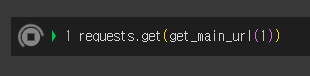
그런데 계속 실행중이다. 완료가 되지 않는다.
알아본 결과 그 이유는, 어떤 웹 사이트들은 요청에 대해 user agent 헤더를 필요로 하기 때문이라고 한다.
이게 뭔지 여기서는 중요한 게 아니니, 관련해서는 알아서 찾아보도록 하자!
헤더 값을 넣어주고 요청을 보내니 응답이 잘 오는 것을 확인할 수 있다.
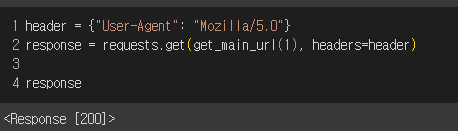
이제 접근하려는 페이지의 html 문서를 받아올 수 있다.
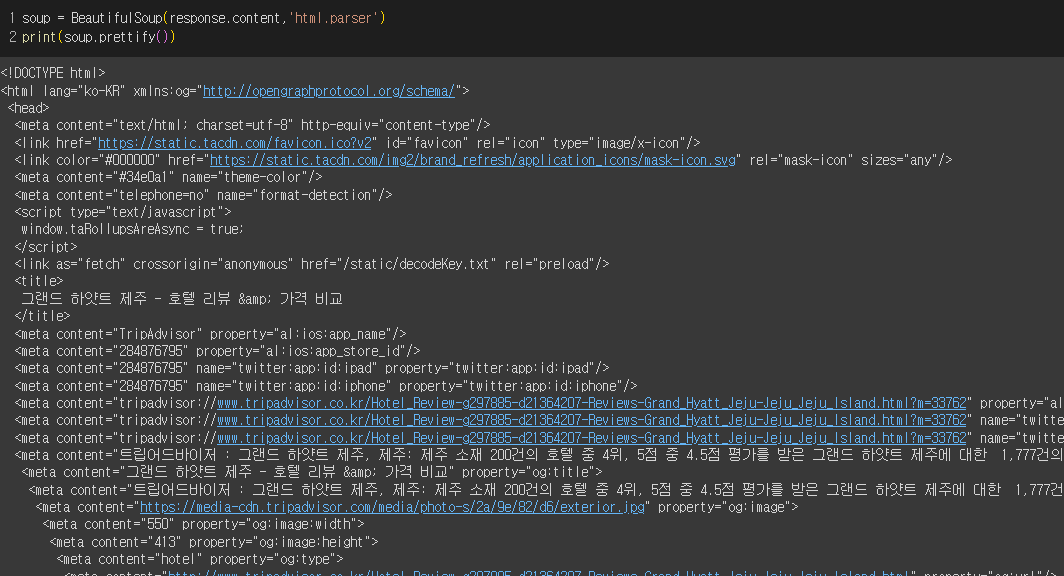
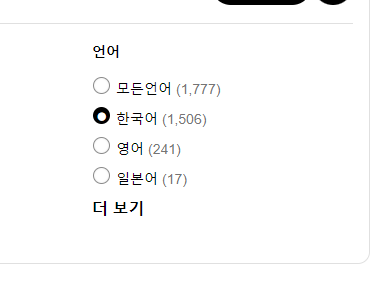
이제, 리뷰 수와 총 페이지 수를 구해보자. 리뷰는 한국어 리뷰로 한정한다.
메인 페이지에 들어가서 한국어 리뷰가 몇갠지 보자(이 글 작성 시점인 24년 3월 21일 기준).
그리고 가져온 html 문서도 보자.
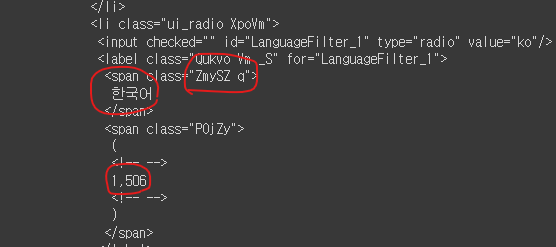
class는 ZmySZ q이고, string은 한국어인 span의 부모 element 중 label이라는 tag를 갖는 element를 찾으면 한국어 리뷰가 1,506개라는 내용이 담긴 html 문서 일부 가져올 수 있을 것 같다.
이렇게!

이제 여기서 리뷰 숫자만 추출하면 되겠다.
위와 같은 과정을 반복하면 된다. korean_tag에서 class가 POjZy인 'span'을 찾아 text로 변환하면 될 것 같다.
전체 페이지 수도 바로 구할 수 있다. 페이지 하나당 리뷰가 5개씩 있는 걸 이미 확인했다.
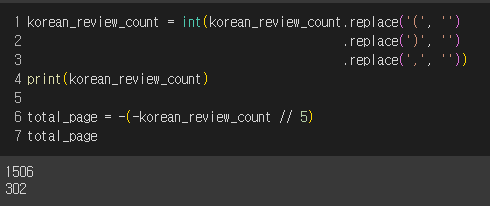
여기까지, Process 1을 진행했다.
To be continued...
'Data Analysis > 개인 프로젝트' 카테고리의 다른 글
| [호텔 리뷰 분석 - 웹 스크래핑] 4. Process(3) (0) | 2024.03.21 |
|---|---|
| [호텔 리뷰 분석 - 웹 스크래핑] 3. Process(2) (0) | 2024.03.21 |
| [호텔 리뷰 분석 - 웹 스크래핑] 1. 어떤 데이터를 어떻게 가져올 것인가? (0) | 2024.03.21 |
| [개인 데이터 분석 프로젝트] (0) | 2024.02.11 |


