Min Max 정규화는 데이터 전처리 과정 중 Feature scaling 단계를 실행하는 방법 중 하나다.
feature scaling이 무엇이며 왜 하는지에 대해서도 작성하고 싶은데, 이는 구글링 해 보면 굉장히 많은 자료가 나오기도 하고, 솔직히 조금 귀찮기 때문에 따로 작성하지는 않을 것이다(나중에 추가로 작성해서 넣을지도??)
Min - Max 정규화가 뭔가요?
Min-max noramlization는 독립변수들의 값이 0~1 사이에 위치하도록 변경시켜 주는 feature scaling 방법이다.
좀 풀어서 설명해보자면, 최대값과 최소값의 범위 내에서 정규화 할 값이 어느 정도의 위치를 갖는지를 0~1사이의 값으로 바꿔 주는 것이다.
공식은 이렇다.
x−xminxmax−xmin
위 공식은 어떻게 나온 것인가요??
예를 들어 데이터의 범위가 10부터 20이고, 정규화하고자 하는 x값이 14라고 하자.
10과 20 사이에서 14는 0.4정도의 위치를 갖는다(0~10 사이에서 4가 어느 위치에 있는지 생각해보자. 그와 같다.)
즉 x가 10~20의 범위일 때 14를 정규화 하면 정규화 하면 0.4가 되는 것. 백분율을 구하는 것과 같다.
만약 6이 200의 몇%인지를 구하고 싶다면 어떻게 하는가?
=> 6을 200으로 나눈다. 6은 0~200 범위 사이에서 0.03의 위치를 갖는다. %로는 3%.
이번엔 150~350의 범위 내에서 156이 몇 %인지, 어느 정도의 위치를 갖는지를 알고 싶다고 하자.
이는 사실상 위에서 봤던 6이 200의 몇%인지를 구하는 문제와 같다. 어떻게 하면 되는가?
(156-150) / (350-150)
이를 공식으로 표현해보면?
(x - x_min) / (x_max - x_min)
=> (정규화 할 값 - min값) / (max값 - min값)
직접 해보자
공식을 이용해서 직접 진행해도 되고, Sklearn에서 제공하는 MinMaxScaler를 이용해도 된다.
두가지 방법을 모두 사용해보고, 같은 값이 나오는지 확인해볼 것이다.
이를 위해 간단한 예시 데이터를 만들자.

1. 손으로 직접
별로 어렵진 않고, 공식에 잘 대입만 해 주면 된다.
2. Sklearn의 MinMaxScaler 사용
sklearn에서 제공하는 MinMaxScaler를 불러오고,
=> MinMaxScaler 객체를 생성해주고,
=> .fit() 메서드를 사용해주면 된다.
3. 비교
뭐 당연히 똑같을 것 같지만, 비교해보자.
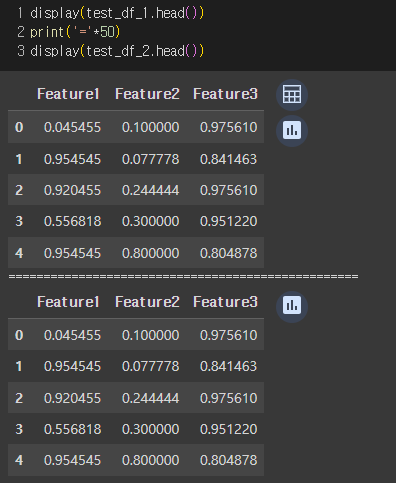
역시나 같은 결과가 나온다.
편한 방법을 택하면 될 것이다.
근데 손으로 하는 것 보단 Sklearn으로 하는게 더 편하지 않을까 싶다.
** feature scaling은 주로 모델링 시 성능 향상을 위해 사용되지만, 당연히 그럴 때만 사용해야 하는 것은 아니고 최대 최소값의 범위가 많이 다른 두 데이터가 있다고 할 때, 그 두 데이터의 변화 패턴을 자세히 비교해 보고 싶을때에도 사용할 수 있다.
그러니까 이런 것이다.
정규화 전
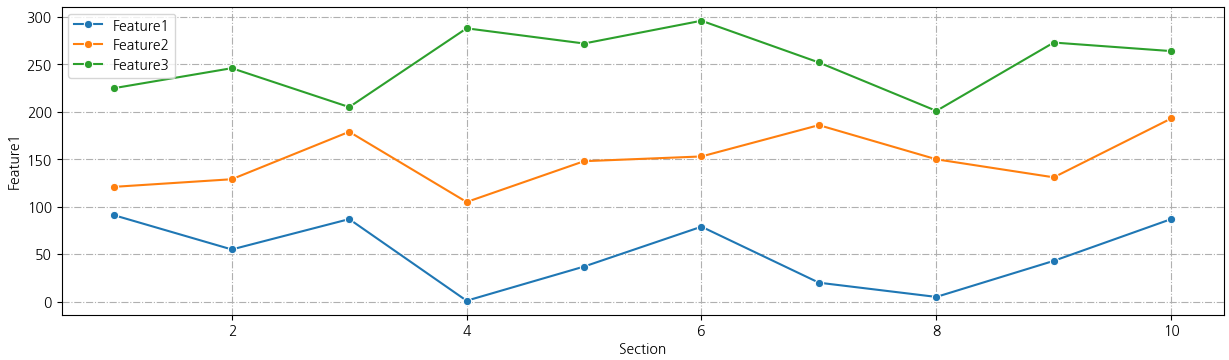
feature 1, 2, 3의 범위가 달라서 어떤 feature가 많이 변하고 적게 변한건지 한 눈에 들어오질 않는다.
이럴 때 정규화를 사용해볼 수 있다.
정규화 후
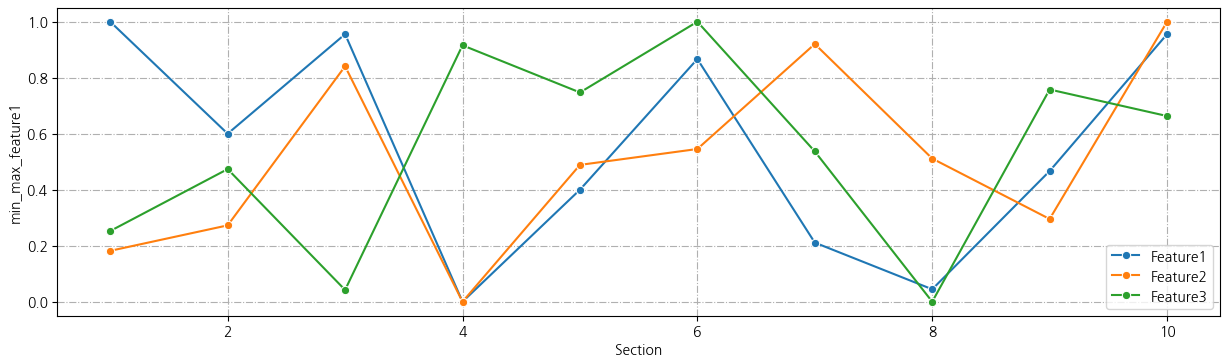
각 feature의 범위를 0~1로 바꾸어놓았기 때문에 각 feature별 변화 양상을 비교하기 쉬워졌다.
'STUDY > Python' 카테고리의 다른 글
| [visualization] 지도 시각화 - folium 소개 및 간단 사용법 (1) | 2024.04.01 |
|---|---|
| [Pandas] 데이터 그룹별 집계 - NamedAgg (0) | 2024.03.22 |
| [Python] 웹 크롤링 - requests 라이브러리 소개 / "기본" 사용법 (0) | 2024.03.20 |
| [Python] html parser - BeautifulSoup (0) | 2024.03.20 |
| [Python] 패키지 / 객체 지향 프로그래밍 / 클래스 (0) | 2024.03.19 |



