이 글은 24.02.14에 본인 벨로그에 작성했던 글을 옮겨 온 것이다.
Project 4. HR 데이터를 통한 채용 기획하기
시나리오
- HR팀의 신입 데이터 분석가가 된 본인... 아래와 같은 업무를 맡게 되다!

Python
데이터 훑어보기
데이터 불러오기
- 데이터 출처 : https://www.kaggle.com/datasets/rishikeshkonapure/hr-analytics-prediction
- Data import
1) import pandas as pd
: DataFrame을 읽을 pandas import
2) from google.colab import drive
drive.mount('content/drive')
: colab과 내 google drive 연결
3) %cd '파일경로'
: 작업 폴더 변경. 굳이 해 주지 않아도 괜찮지만, 변경해주는게 더 편하다. 후에 데이터나 이런 것들을 불러올 때 경로 지정을 따로 해줄 필요가 없기 때문.
데이터 훑어보기
1) .columns : 데이터프레임의 컬럼 확인

2) .info() : 데이터프레임 기본 정보 확인. 컬럼, 컬럼의 데이터 타입, 데이터 수 등등
=> 총 1470행인데, 데이터도 모두 컬럼별로 1470개씩 있는 걸 보아 null값은 없다.

3) .describe() : 각 컬럼별(numerical column) 기술통계량 확인.

4) .describe().T : .describe()와 같은 것을 출력하지만, 전치해서 출력.

5) 깔끔하게 보기
=> df의 기본 정보를 다시 df로 만들어서 보면 된다

데이터 자세히 보기
unique값이 하나만 있는 컬럼들이 있다
=> 그 어떤 행에도 다 같은 값을 가지기 때문에, 굳이 있을 필요가 없다. 제외해준다.
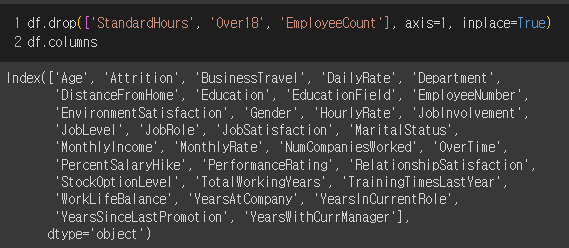
사내 조직 파악하기
groupby()
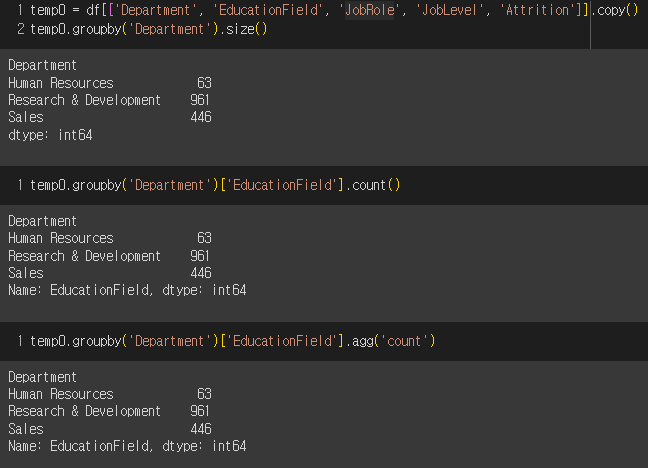
1) 각 부서에 몇 명이나 있을까?
=> HR부서엔 63명, R&D 부서엔 961명, Sales 부서엔 446명의 사원이 있다.
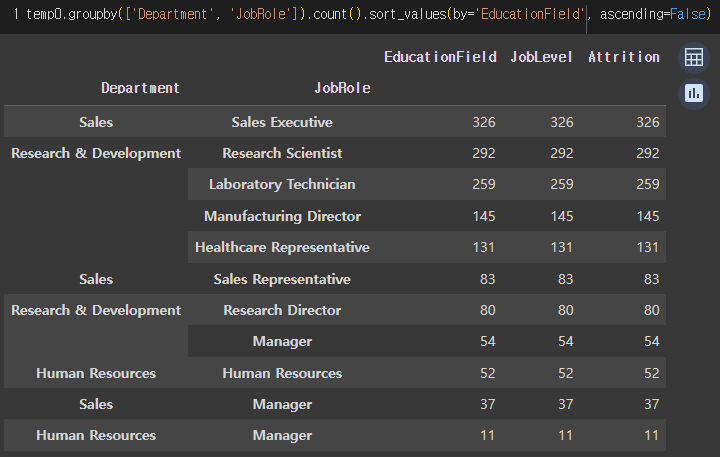
2) 각 부서에 있는 Job role 현황은 어떻게 될까?
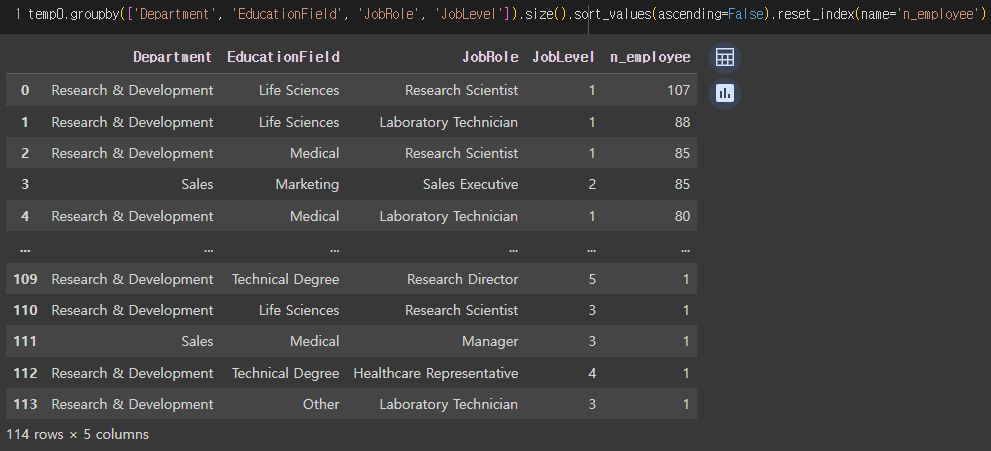
3) 각 부서별 다른 컬럼 값은??(job role, job level, .. 등)
=> 각 부서별 각 컬럼별 사원 수를 볼 수 있다.
=> 예를 들어 맨 첫번째 행의 경우, R&D부서에 생명과학을 전공하고 직무는 research scientist이며 job level이 1인 사원은 총 107명이 있다는 것.
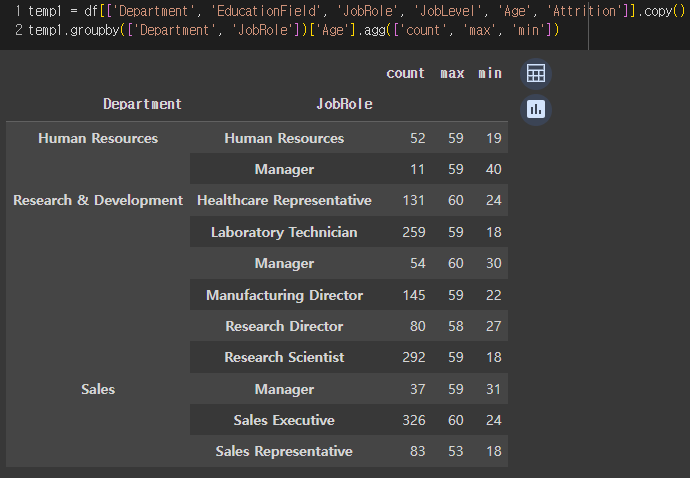
4) 나이도 고려해보자. 부서별 job role별 age의 분포.
=> HR부서의 HR직무는 총 52명이 있고, 최연장자는 59살이며 최연소자는 19살이다.
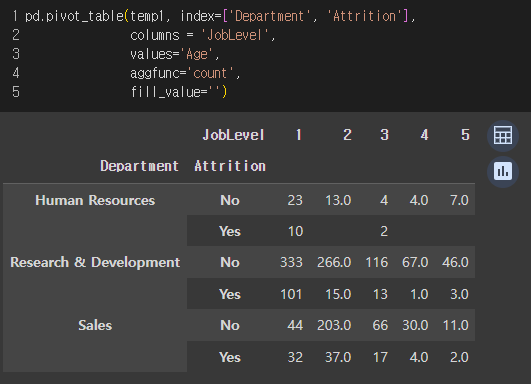
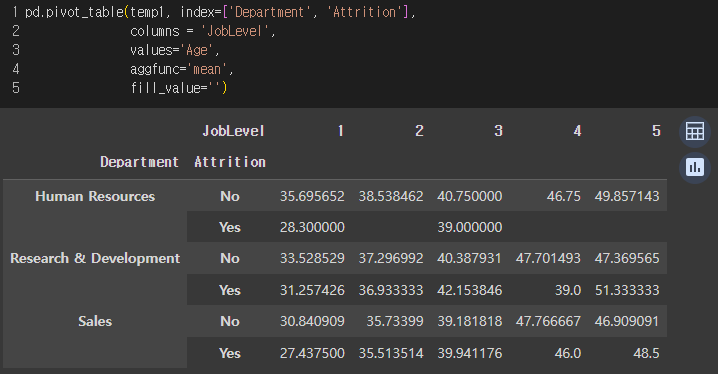
pivot_table()
부서별 퇴직 여부와 job level별 사원 수 및 나이의 평균
=> HR부서 현직자(퇴직No) 중 job level이 1인 사원은 23명이며, 해당 사원들의 평균 나이는 35.7세.
=> fill_value 파라미터는, 출력 결과에 null이 있을 경우 어떤 값으로 대체하겠는가를 정해주는 파라미터다.
stack / unstack
- multi index에만 stack과 unstack을 사용할 수 있다.
=> pivot1의 index는 Department, Attrition
=> pivot2의 index는 Department, Attrition, JobRole

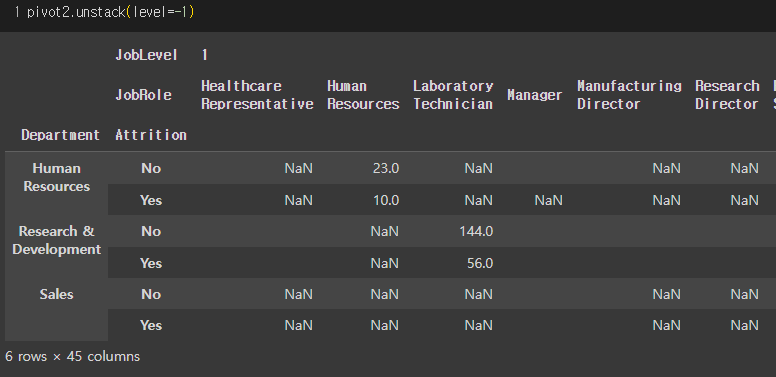
1) Unstack
=> 원본 pivot2
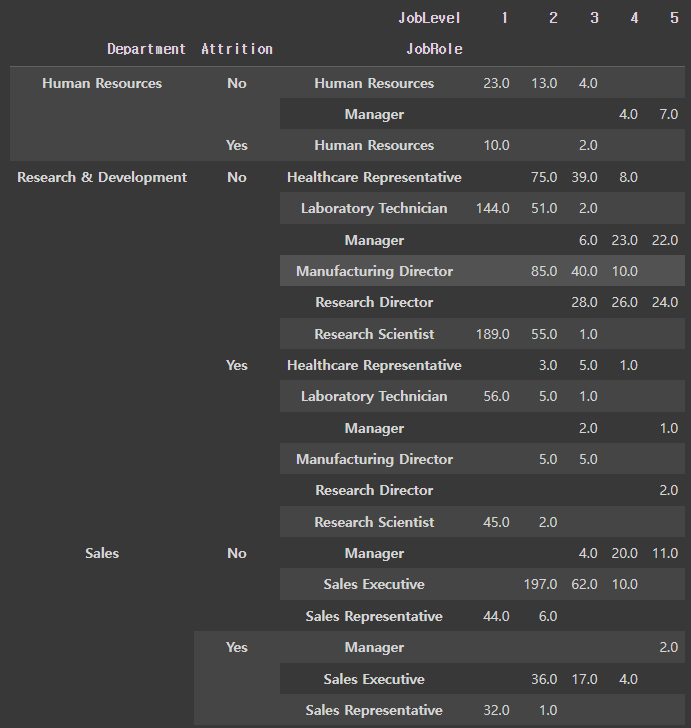
=> pivot2.unstack(level = -1) (level=-1이 기본값이라서 생략 가능)
=> stack : 쌓다, unstack : 쌓지 않다. level은 multi index의 index를 의미한다.
=> 이 경우 pivot2의 index는 Department, Attrition, JobRole이고, -1 위치의 index는 JobRole
=> level에 해당하는 index를 column으로 보내는 것이 Unstack
2) Stack
=> 이름만 봐도 unstack의 반대일 것 같다. column을 index로 보내는 것. 이 역시 level의 기본값은 -1이다.
시각화(Matplotlib, Seaborn)
Heatmap
- numeric columns 상관관계 Heatmap으로 시각화하기
1) numeric columns만 골라내주자.
2) 무작정 그려보기. 아무 parameter도 안 넣고.
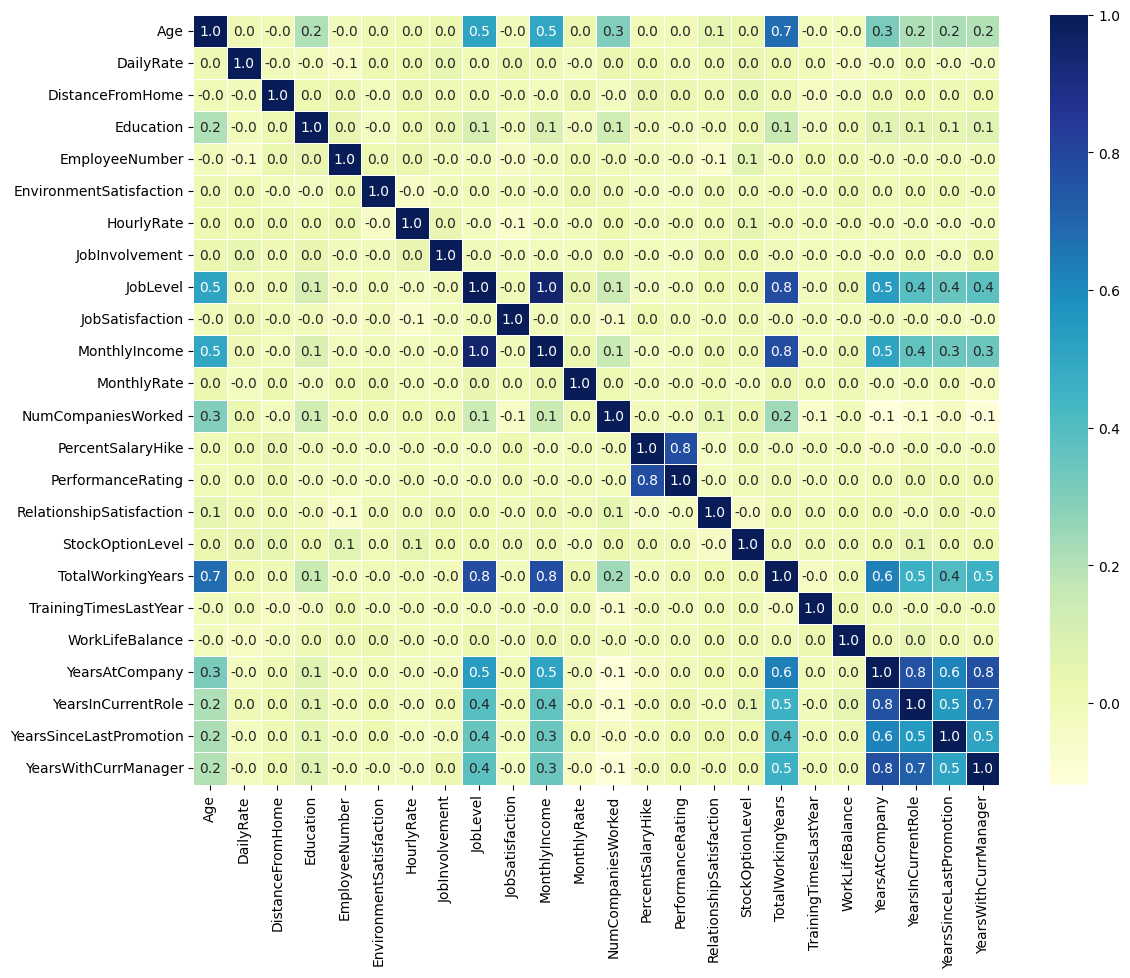
3) 이것저것 조정해보자.
plt.figure(figsize=(13,10))
sns.heatmap(df_corr, annot=True, fmt='.1f', linewidth=0.5, cmap='YlGnBu')
plt.show()

4) 컬럼이 너무 많다... 조금 추려내자. 어떻게?
=> 다른 컬럼들과 높은 상관관계를 갖는 컬럼들만 추려내자.
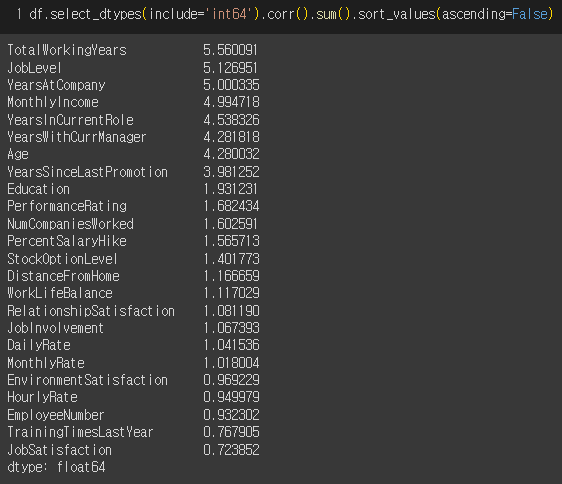
주의점! 전체 컬럼들에서, 전반적으로 음의 상관관계가 크게 나타나는 경향이 있다면 이 방법은 위험함. 그냥 다 더한 것이기 때문.
하지만 이 데이터프레임에선 음의 상관관계가 크게 나타나지 않아서 이런 식으로 찾아도 괜찮다.
1점대 이상인 것들만 고르면 좋을 것 같다.
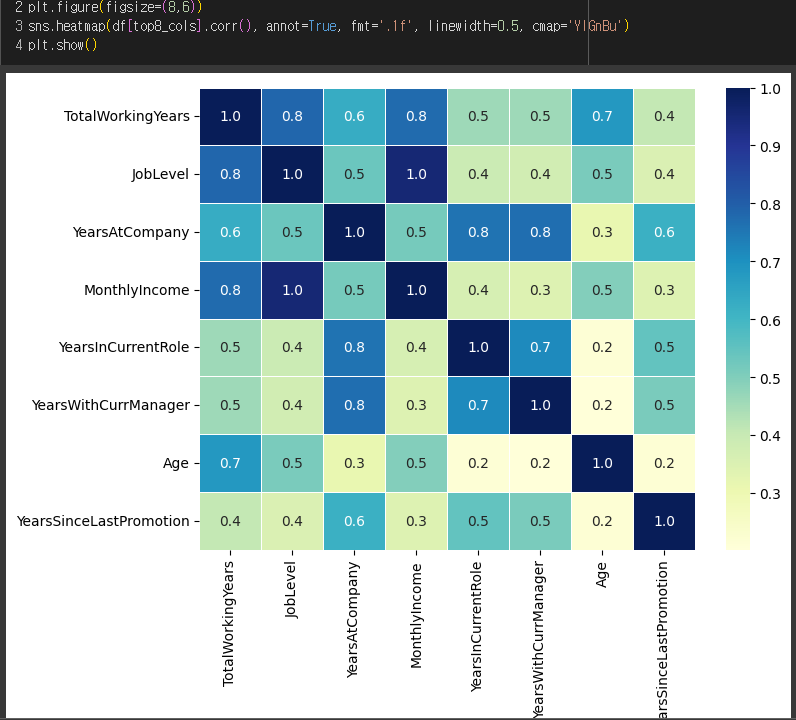
5) 그려보자.
=> 여기서 볼 수 있는 양의 상관관계는?
=> joblevel과 totalworkingyears. 오래 일할 수록 직급 업업업
=> joblevel과 monthlyincome. 직급이 높을수록 월급도 많다.
=> 그 외 다양한 양의 상관관계를 확인할 수 있음.
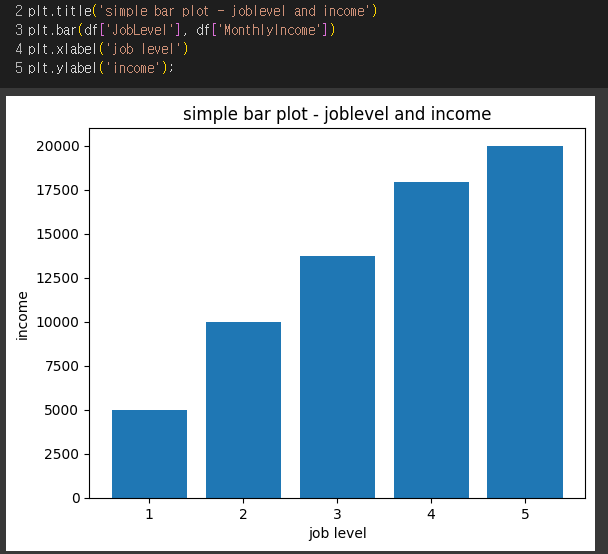
막대그래프
1) Matplotlib - job level과 income
job level과 income의 관계가 명확하게 보인다. 직급이 높을수록 월급도 높다
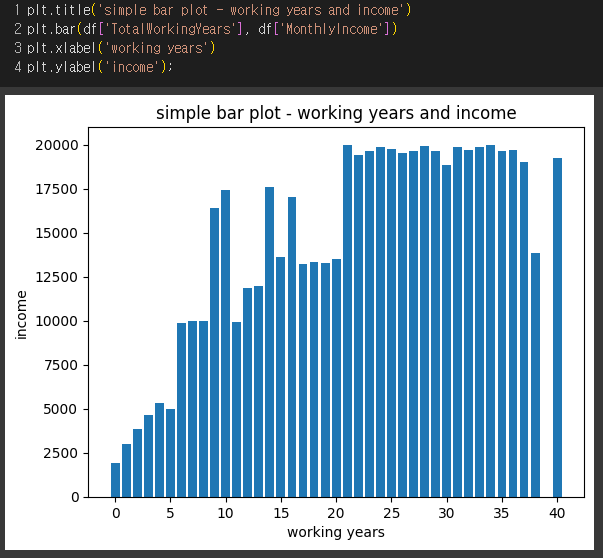
2) Matplotlib - working years와 income
대개는 근속연수와 월급이 비례하지만, 아닌 연차도 있다.
=> 의문점 : 왜 항상 비례하는 것이 아닐까? 저연차에도 월급을 많이 받는 부서가 있을까?
=> drill down 해보자.
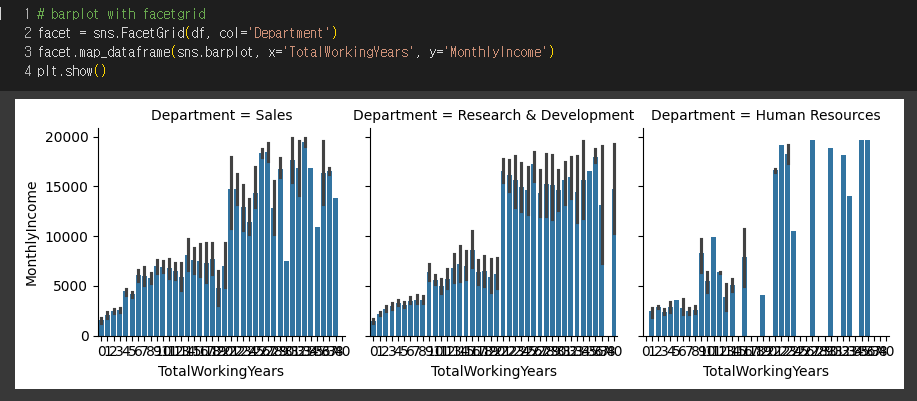
3) Seaborn.FacetGrid - 부서별 working years와 income
=> 부서별로 나눠 보았지만, 부서별 경향이 비슷했다. 다만, HR에서 다른 두 부서와 조금은 다른 경향이 보인다.
4) 3)에서 좀 더 drill down해보자. 이번엔 row에 job level 추가
facet = sns.FacetGrid(df, col='Department', row='JobLevel', height=6)
facet.map_dataframe(sns.barplot, x='TotalWorkingYears', y='MonthlyIncome')
facet = facet.fig.subplots_adjust(wspace=.4, hspace=.2)
plt.show()5) 야근여부와 부서, 재직 여부에 따른 워라밸과 직업만족도의 관계
facet = sns.FacetGrid(df, col='OverTime', row='Department', hue='Attrition', hue_order=['No', 'Yes'], height=6, palette={'Yes' : 'red', 'No' : 'gray'})
facet = facet.map_dataframe(sns.barplot, x='WorkLifeBalance', y='JobSatisfaction')
facet = facet.add_legend();이렇게, 여러 조건을 걸어서 그래프를 세세하게 drill down해서 출력할 수 있다.
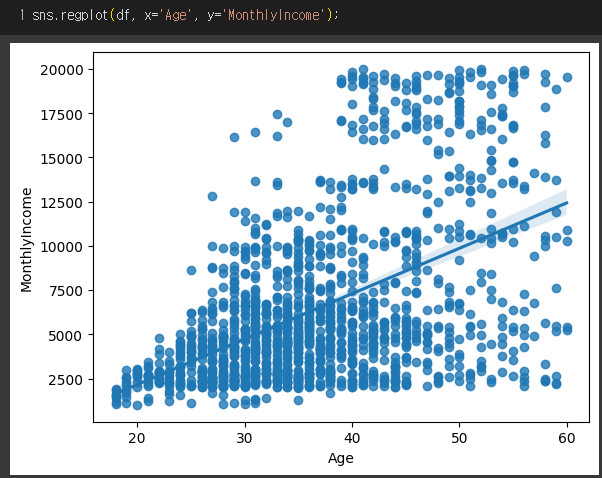
Reg plot(scatter plot)
- 추세선까지 표시되는 scatter plot
1) 기본 reg plot
=> 나이대별 월급 분포
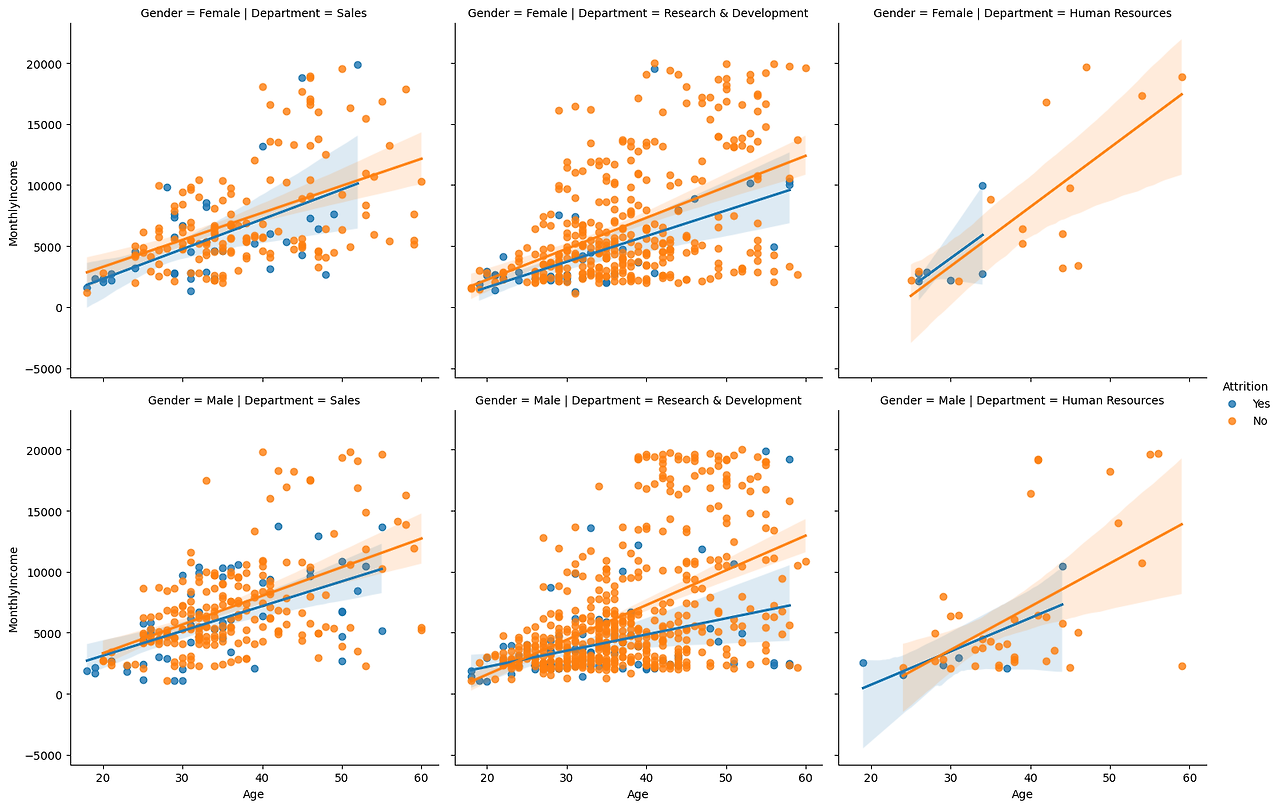
2) regplot with facetgrid
=> 재직 여부와 성별, 부서에 따른 나이대별 월급 분포
facet = sns.FacetGrid(df, col='Department', row='Gender', hue='Attrition', height=5)
facet = facet.map_dataframe(sns.regplot, x='Age', y='MonthlyIncome')
facet = facet.add_legend();
=> 보이는 것?? 나이가 많은 퇴사자(이직??)일수록 월급이 높다. R&D부서에서 뚜렷하게 나타남. 연차가 쌓이면 좀 더 고연봉으로 이직을 하는 것일까?
histplot(+enumerate 반복문)
- histplot으로 데이터의 분포를 보는데, 반복문으로 좀 편하게 그려보고 싶다.
1) 기본 histplot
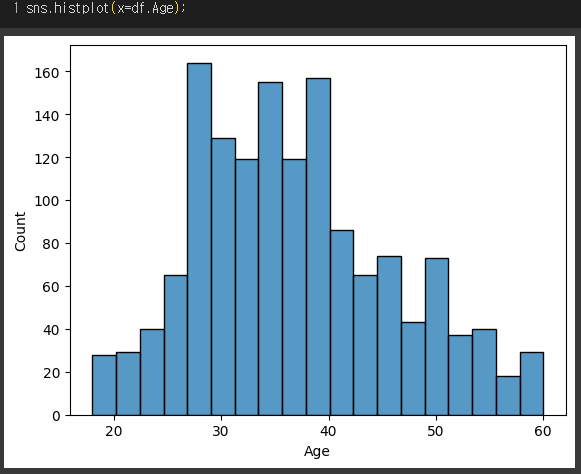
=> Age의 분포
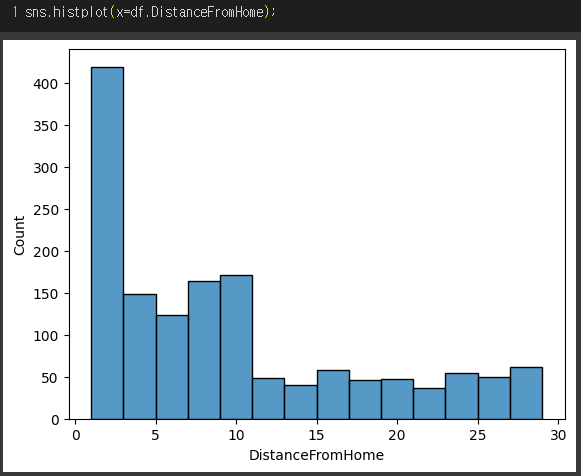
=> 통근거리의 분포
2) 컬럼들이 굉장히 많아서 위처럼 하나하나 그리기엔 번거롭다. Enumerate 반복문을 사용하자.
=> 보고 싶은 것은 성 별 각 컬럼 데이터의 분포.

SQL(MySQL)
DBeaver
- DBeaver(디비버) 란?
MySQL, PostSQL, SQLite, Oracle, DB2, SQL Server, Sybase, MS access, Teradata, Firebird, Apach Hive, Phoenix, Presto... 등등 거의 모든 데이터 베이스에 연결해서 쿼리를 보낼 수 있는 툴이다.- 장점
1) 오픈소스
2) 무료
3) 직관적인 인터페이스
4) 다양한 DB 지원
5) Data import, export 쉬움
6) ERD 그려볼 수 있음- 단점
무거운 쿼리를 실행 시킬 경우 다운 될 수 있음.
설치해보자.
설치 파일이 다운로드 되면 실행하고, 다음, 다음, 다음, ... 을 눌러주면 설치 끝!
'Data Analysis > Data Analysis' 카테고리의 다른 글
| Project 4. HR 데이터를 통한 채용 기획하기 (3) (1) | 2024.03.30 |
|---|---|
| Project 4. HR 데이터를 통한 채용 기획하기 (2) (1) | 2024.03.30 |
| Project 3. 고객행동 분석을 통한 서비스 헬스체크 (1) | 2024.03.30 |
| Project 2. 이커머스 데이터를 통한 사업 동향 파악 (3) (1) | 2024.03.30 |
| Project 2. 이커머스 데이터를 통한 사업 동향 파악 (2) (1) | 2024.03.30 |



