즉,데이터 분석가는 raw 데이터 처리, 데이터 분석, 리포팅까지의 모든 업무를 할 수 있어야 한다!
이번 프로젝트에서는 위에서 언급했던 것과 같이 주류 산업의 데이터 분석 컨설턴트가 된 본인이 아래와 같은 업무를 맡았다고 가정한다.
해당 지역(여기서는, 데이터가 수집된 미국 아이오와 주를 의미함)의 주류 판매 시장의 동향은 어떤지 알려달라.
어느 지역에 어떤 상품을 주력으로 팔아야 할 지, 관련 인사이트를 제공해 달라.
이제, 분석 컨설턴트로서의 업무를 시작해 보자.
Raw 데이터 처리
Spark, 중에서도 Pyspark를 활용할 것이다.
Spark의 구조와 데이터 처리 방식
우선은Spark의 구조와 데이터 처리 방식에 대해 알아보자!
스파크?뭔가요??
범용적 목적을 지닌 분산 클러스터 컴퓨팅 오픈소스 프레임워크.
분산 클러스터란건 뭔가요?
전반적인 시스템 성능 향상을 위해 계산을 여러 노드에서 분담해서 병렬 처리하도록 구성하는 방식. => 여러 컴퓨터의 자원을 모아 하나의 컴퓨터처럼 사용하는 것. 스파크의 구조는 아래 그림과 같다.
Cluster Manager
사용 가능한 자원을 파악하고, 클러스터의 데이터 처리 작업을 조율한다.
사용자는 클러스터 매니저에 스파크 어플리케이션을 제출하여 작업을 하게 된다.
스파크 어플리케이션은 Driver Process와 Executor로 구성되어있다.
Driver Process
스파크 어플리케이션의 구성 중 하나이기도 하고, 클러스터 노드 중 하나이기도 하다.
스파크에서 하고자 하는 작업을 Executor에게 보내는 역할을 한다.
각 클러스터 당 하나만 존재한다.
Spark session, User code로 구성된다.
Spark Session
스파크의 기능과 구조가 상호작용하는 방식을 제공해주는 컴포넌트.
Executor Process
Driver process에서 할당받은 작업을 수행한다.
진행 상황을 다시 Driver process에 보고한다.
Spark의 데이터 처리 방식(1) - Partition
모든 Executor가 병렬로 작업을 수행할 수 있도록 'Partition'이라 불리는 단위로 데이터를 분할. => 파티션은 클러스터에 존재하는 행의 집합 => 스파크의 성능(병렬성)은 파티션과 익스큐터의 수로 결정된다.
Spark의 데이터 처리 방식(2) - Transformation
사용자가 데이터의 변경을 원할 때(ex. 쿼리를 날리거나 등등...) 변경 방법을 Spark에게 알려주는 단계
이 단계에서 Spark는 데이터 처리의 논리적 실행 단계를 계획한다 => 즉실제 연산이 일어나지는 않는다.
Spark의 데이터 처리 방식(3) - Lazy Evaluation & Action
1) Lazy Evaluation 특정 연산 명령이 내려진 경우, raw 데이터에 적용할 transformation만 실행한다. => Action 전까지의 transformation을 모두 실행해서, 전 과정을 최적화하게 된다. => 데이터 흐름을 최적화하는 과정.
2) Action 실제 연산을 수행하는 과정. ex) 카운트, 데이터 출력, 데이터 저장 등.
- 카탈리스트란? :transformation을 적용할 때 스파크 SQL은 논리 계획이 담긴 tree 그래프를 생성하는데, 이를 카탈리스트라 한다. => 카탈리스트에 의해 action을 위한 최적의 논리로 데이터가 반환되기 때문에 성능이 좋다.
PySpark
Python 환경에서 Apache Spark를 사용할 수 있는 인터페이스.즉, Spark용 파이썬 API
Pyspark의 기능과 라이브러리엔 다음과 같은 것들이 있다.
1) Spark SQL and DataFrames
2) Pandas API on Spark
3) Structured Streaming
4) Machine Learning(MLib)
이제 PySpark를 직접 사용해보자! 구글 코랩에서 진행한다.
PySpark 환경설정
아래와 같이 코드를 실행해주자. 최신 버전은 아니지만, pyspark를 직접 사용하는 것이 더 중요하므로 넘어가도록 하자.
pyspark 객체 생성
생성된 pyspark객체의 설정 알아보기
Kaggle API로 데이터 불러오기
PySpark로 데이터 처리를 하려면? 당연히 데이터가 있어야 한다. 직접 다운 받던 외부에서 가져오던 어쩌던 상관 없으나 보통은 다운로드를 받지. 하지만 그 데이터가 용량이 굉장히 크다면?
이런 경우엔 직접 다운받는 것이 아니라, API를 사용해서 데이터를 불러오곤 한다. 캐글에서 우리가 사용할 아이오와 주 주류 판매 데이터를 API를 이용해 가져와 볼 것이다.
우선, 캐글에 접속해서 우측 상단 계정 아이콘 - Settings - Account 항목의 API를 확인해보자. Create New Token을 누르면, 해당 계정의 kaggle api token이 json 파일로 다운로드 된다.
이전에 발급받은 토큰이 있고 잃어버리지 않았다면 굳이 create 할 필요는 없으나, 잃어버렸다면 Expire Token 진행 후 Create 하도록 하자.
이제, 다운받은 토큰을 구글 코랩에 올려주자. 아래 코드 실행 후 파일 선택을 눌러서 토큰을 업로드하면 된다.
이후, 아래 코드를 실행시키면 데이터를 받아올 수 있다.
파일 크기가 6GB에 달한다.
이제 데이터를 dataframe 형태로 불러와보자. 크기가 커서 꽤나 시간이 걸린다 (Pandas의 dataframe 아님 주의)
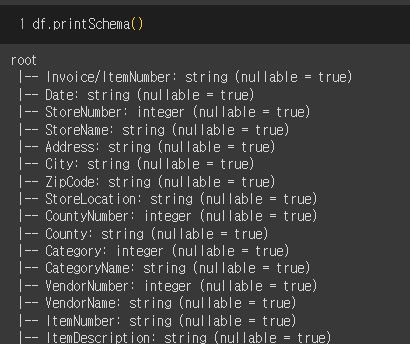
데이터가 잘 불러와졌다! 컬럼도 확인해볼 수 있다.(df.columns 도 가능)
PySpark로 데이터 저장하기
빅데이터를 이용한 파일 포맷엔 여러가지가 있다.
이 중에Parquet는 PySpark에 특화된 파일 포맷이다. 해서, 불러온 데이터를 Parquet 파일로 저장해 볼 것이다.
parquet에 사용할 수 없는 문자들이 있다. 공백, 괄호 등이 있다. 컬럼명에 해당 문자들이 있다면 저장할 수 없으므로, 바꿔 주어야 한다.
바꿔주고 나서, df 데이터를 parquet 포맷으로 바꿔주자. 시간이 꽤 걸린다.
PySpark로 데이터 훑어보기
이제 직접 PySpark를 사용해보자. 우선 데이터 파악부터.
PySpark로 전처리하기
PySpark sql function을 사용할 것이다.
결측치 처리
아래 함수를 실행해보자. 컬럼 별 null값을 얻을 수 있다.
isNull(), isNotNull함수는 대/소문자가 구분됨에 유의하자. 즉 isnull(), isnotnull()로 하면 실행 안된다는 말.
데이터 분석 컨설턴트인 본인의 이번 업무는 해당 지역(여기서는, 데이터가 수집된 미국 아이오와 주를 의미함)의 주류 판매 시장의 동향은 어떤지, 어느 지역에 어떤 상품을 주력으로 팔아야 할 지, 관련 인사이트를 제공하는 것이다. 즉 구체적인 위도나 경도는 필요 없다는 말이므로,가게의 위/경도를 나타내는 StoreLocation 컬럼과 CountyNumber 컬럼은 필요 없을 것 같다. 없애주자.
지역 정보("Address", "City", "ZipCode", "County") 중 가장 null값이 적은 정보는? County 빼고는 비슷비슷 하지만, City가 제일 적다 => City가 null값인 행은 다 빼주자. => 결측치가 많은 Address, Zipcode, County 컬럼도 빼버리자
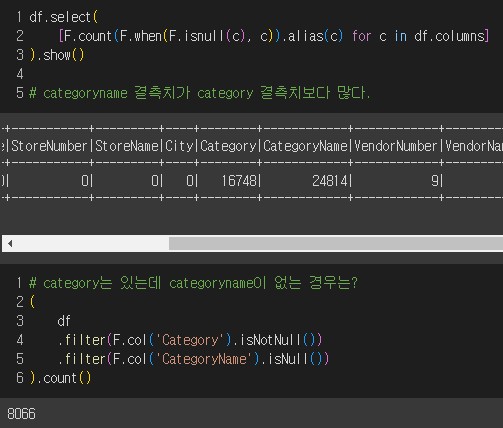
다른 컬럼의 null값들도 더 뜯어보자.
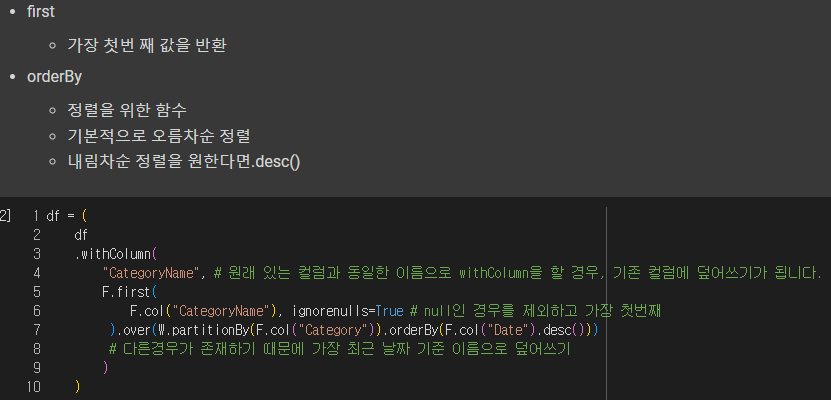
동일 카테고리에 카테고리 네임이 다른 경우도 있을까? 있었다!
그러한 카테고리 네임을, 가장 최신 버전으로 덮어씌워 하나의 카테고리엔 하나의 카테고리 네임만 남도록 할 것이다.
결측치를 마저 처리해 보자. category와 categoryname의 결측치.
데이터 형 변환
시각화 - Plotly
전부 다 시각화를 해 볼 필요까지는 없고(하고싶다면 해 보도록 하자!), 특정 city 데이터만 시각화 해 보자. 우선 시각화할 수 있게 pandas dataframe으로 바꿔주자.
plotly 설치 해 주고...
시각화 할 수 있도록 groupby로 데이터 전처리
이제 간단한 시계열 그래프를 그려 보자. plotly의 장점은 interactive한 그래프를 그릴 수 있다는 것이다.
그런데, matpltlib이나 seaborn에 비해 코드가 복잡하다. 더 쉽게 쓸 수는 없을까? => 있다! plotly의 express 패키지를 사용하면 된다.
커스터마이징은 좀 덜 가능할지 모르지만, 훨씬 간단하게 그래프를 그릴 수 있다.
시장 동향 파악
매출 추이와 성장률
전체적인 성장세를 알아보고자 한다. 성장세는 무엇으로 판단할 수 있는가? -매출이 증가하고 있는가? -점포 수가 증가하고 있는가?
우선은 보고자 하는 정보에 맞춰 데이터를 전처리한 후 pandas로 바꾸자
그리고 나서 plotly의 express 패키지를 이용해서 매출과 상점 수의 변화를 선 그래프로 그려보자. 꾸준히 성장하고 있는 것으로 보인다.
매출의 성장률을 보고 싶다.
위의 결과들로 미루어보아 주류 시장 전체의 매출과 점포 수는 꾸준히 증가하고 있다. 허나 매출의 증가율(성장률)이 최근 들어 낮아졌음을 알 수 있다.
영업이익 계산
영업 이익? => 말 그대로, 이것저것 다 하고 남은 순 이익. => 매출 - 매출 원가 - 기타 등등 비용.
PySpark udf를 사용해서 계산해볼 것이다.
udf는 별 게 아니고, user define function의 약자로, 그냥 직접 만든 함수를 pyspark에서 사용하겠다는 것이다. 직접 작성한 함수를 pyspark에서 사용하기 위해서는, udf 객체로 만들어주어야 한다.