[24.02.07]
4주차 18차시 - 통계학 맛보기
모수Population Parameter
1. 통계적 모델링의 목표는 적절한 가정 위에서 확률분포를 추정inference하는 것
2. 이는 기계학습과 통계학의 공통 목표이기도 하다.
3. 그러나 유한한 개수의 데이터만 관찰해서 모집단의 확률분포를 정확하게 알아내는 것은 불가능.
=> 근사적으로 확률분포 추정함
=> 예측 모형의 목적은 정확한 분포를 맞추는 것 보단 데이터와 추정 방법의 불확실성을 고려해서 예측의 위험을 최소화 하는 것 정도면 충분하기 때문.
3-1. 모수적parametric 방법 : 데이터가 특정 확률분포를 따른다고 선험적으로priori 가정한 후, 해당 분포를 결정하는 모수를 추정하는 방법.
ex) 정규분포의 경우 평균과 분산이 중요한 모수임. 이 평균과 분산을 추정하는 방법으로 데이터를 학습.
3-2. 비모수적nonparametric 방법 : 특정 확률분포를 가정하지 않은 경우. 모수가 무한히 많거나, 데이터에 따라 모수의 개수가 바뀌는 경우이지, 모수가 없는 경우가 아님.
모수적 방법론
1. 확률분포 가정 예시
- 데이터가 2개 값(0 or 1)만 갖는 경우 : 베르누이 분포
- 데이터가 n개의 이산적 값을 갖는 경우 : 카테고리 분포
- 데이터가 0, 1 사이의 값을 갖는 경우 : 베타 분포
- 데이터가 0 이상의 값을 갖는 경우 : 감마 분포, 로그 정규분포
- 데이터가 실수 전체에서 값을 갖는 경우 : 정규분포, 라플라스 분포

2. 모수 추정 : 데이터의 확률분포를 가정했다면, 이제 모수를 추정해볼 수 있다.
2-1. 정규분포의 경우

2-2. 표집분포Sampling distribution (표본분포Sample distribution와는 다르다!)
- 표본분포는 표본들의 분포를 의미하는 것이고, 표집분포는 표본 통계량(표본평균, 표본분산 등)의 확률분포를 의미한다.
- 특히, 표본평균의 확률분포(=표집분포)는 N이 커질수록(=데이터가 많을수록) 정규분포를 따른다 => 중심극한정리

3. 최대가능도 추정법MLE(Maximum Likelihood Estimation)
3-1. 확률 분포마다 사용하는 모수가 다르므로, 항상 표본평균이나 표본분산을 모수로 사용할 수는 없다
3-2. 최대가능도 추정법은 가장 중요한(가장 가능성이 높은) 모수를 추정하는 방법 중 하나이다.

3-3. 최대가능도 추정법은 데이터 집합 X의 각 행벡터가 독립적으로 추출되었을 때 로그가능도(log likelihood)를 최적화한다.

3-4. 왜 로그가능도를 사용하는가?? => 연산 가능 여부와 가능도 최적화 관점에서 중요하기 때문.

3-5. 최대가능도 추정법 예제 : 정규분포의 경우.

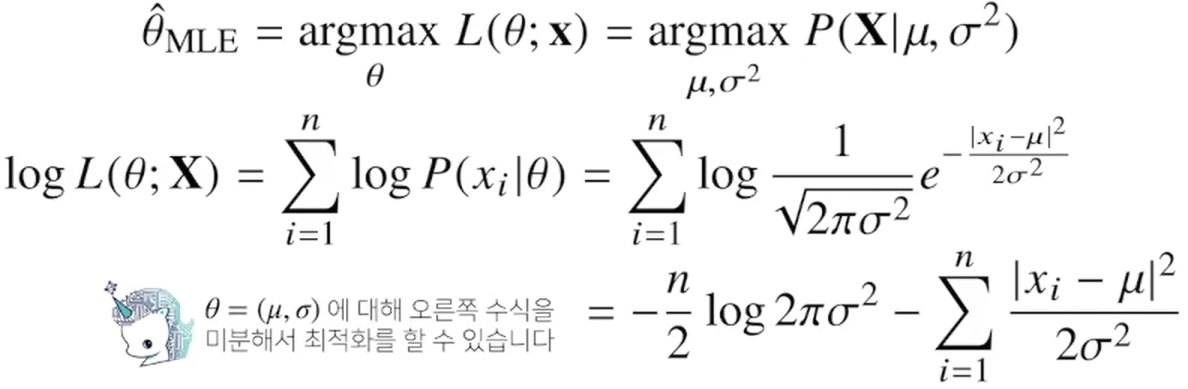
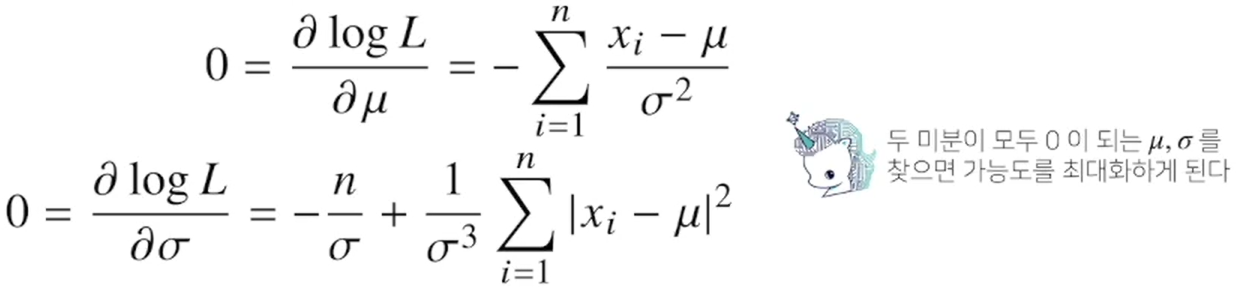
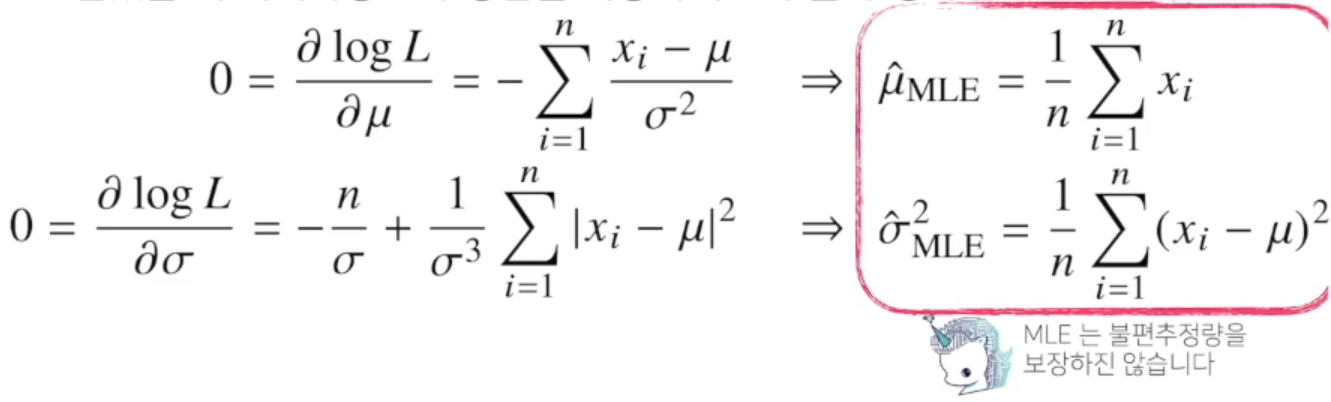
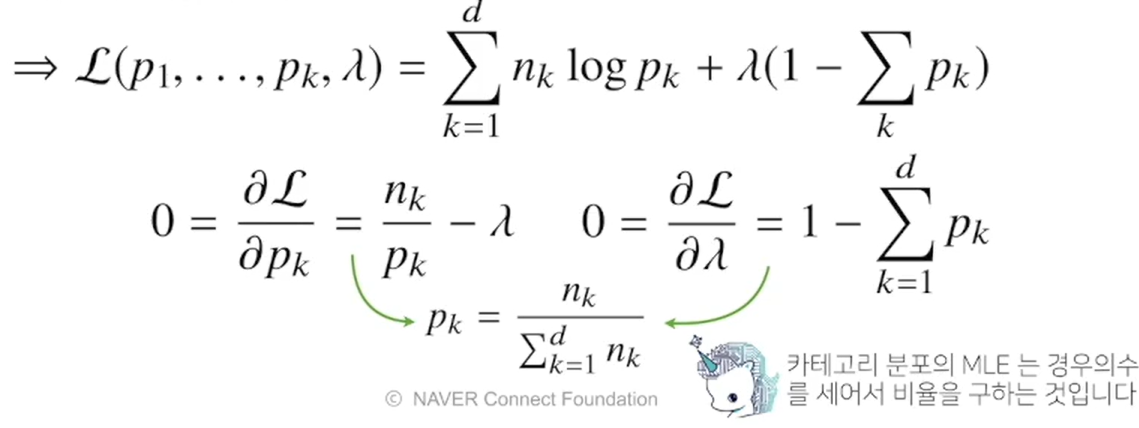
3-6. 예제 2 : 카테고리 분포의 경우
=> 카테고리 분포는 베르누이 분포를 d차원으로 확장시킨 분포라고 할 수 있음.
=> d개의 각 차원에서 어떤 하나의 확률변수를 선택하게 되면 선택변수는 1이고 나머지는 0이 되는 one-hot vector로 변하게 됨.
=> d개의 각 차원에서 하나의 모수를, 즉 p1, p2, ..., p_d를 추정하게 됨.
=> 정규분포의 모수는 평균과 분산이었지만 카테고리 분포에서의 각 모수는 각 차원에서 값이 1 또는 0일 확률이므로, p1 ~ p_d의 합은 1이 된다.

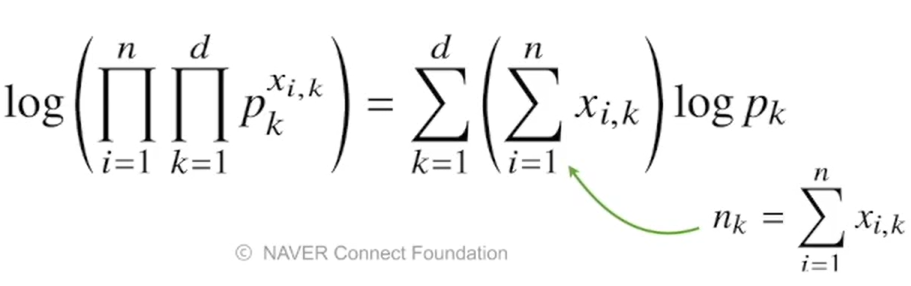
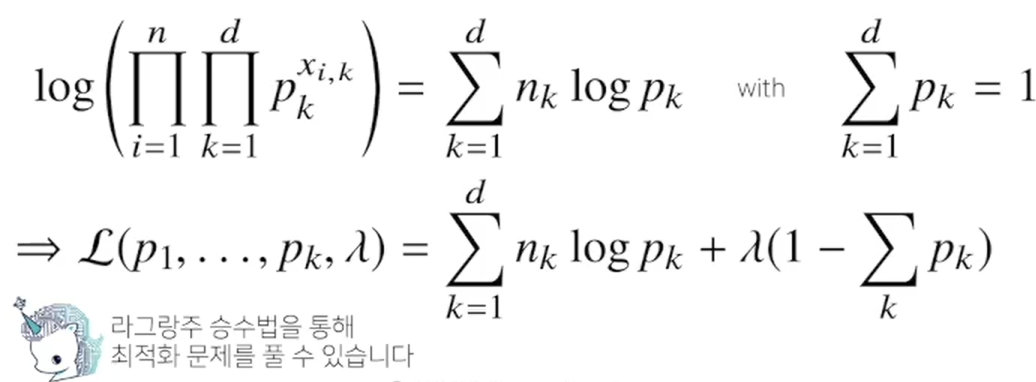
'STUDY > 부스트코스 - AI 엔지니어 기초 다지기' 카테고리의 다른 글
| [AI 엔지니어 기초 다지기] 16일차 (0) | 2024.02.13 |
|---|---|
| [AI 엔지니어 기초 다지기] 15일차 (0) | 2024.02.09 |
| [AI 엔지니어 기초 다지기] 13일차 (0) | 2024.02.05 |
| [AI 엔지니어 기초 다지기] 12일차 (0) | 2024.01.31 |
| [AI 엔지니어 기초 다지기] 11일차 (0) | 2024.01.30 |



