[24.01.31]
3주차 16차시 - 딥러닝 학습방법 이해하기
선형 모델을 간단하게 표시해보면...
대략 아래와 같다. 이는, d개의 변수로 p개의 선형모델을 만들어 p개의 잠재변수를 설명하는 모델이라 볼 수 있다.
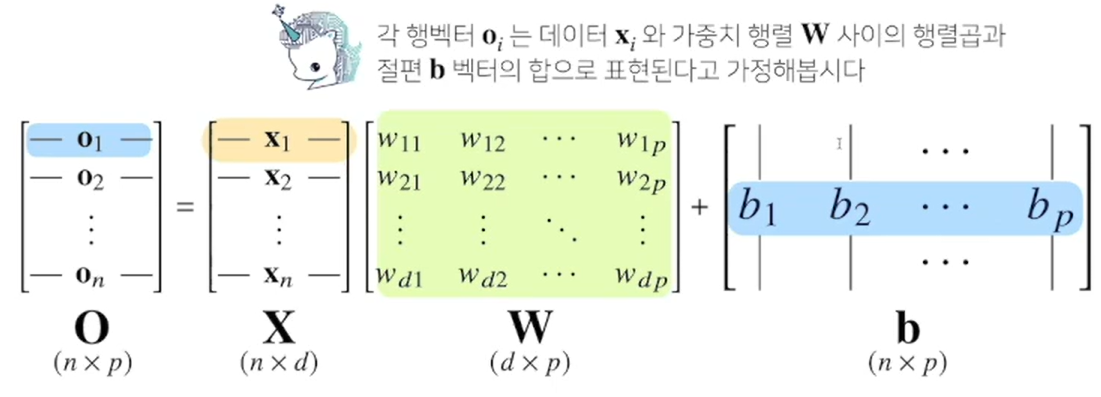

최종 출력 벡터인 O에 softmax 함수를 합성하면, 주어진 데이터가 특정 클래스 k에 속할 확률을 구할 수 있는데, 이를 분류문제라고 부른다.

그런데, softmax함수가 뭐지??
Softmax 함수
- 모델의 출력을 확률로 해석할 수 있게 변환해 주는 연산(함수)이다.
위에서 언급했듯, 분류 문제를 풀 때 선형모델과 softmax 함수를 결합해 사용한다.

- 하지만, 추론인 경우엔 softmax를 쓰지 않는다! (참고)

One-Layer NN(Nerual Network)
- 신경망 = 선형모델 + 활성함수activation function
- DL에서는 선형 모델로 나온 각 출력물을 활성화 함수를 이용해 비선형으로 변환할 수 있고, 이렇게 변화된 출력물(벡터)들의 집합을 잠재벡터(H, Hidden)라 한다. 또한 이런 잠재벡터들을 뉴런이라 부른다.
- 신경망 모델이란, 뉴런들로 이루어진 모델을 말한다.
- 아래 신경망 모델은, 선형 모델을 하나 쓰고 있으므로(단일 층 사용) 1 - Layer Neural Network라 하고, Perceptron이라고도 한다.
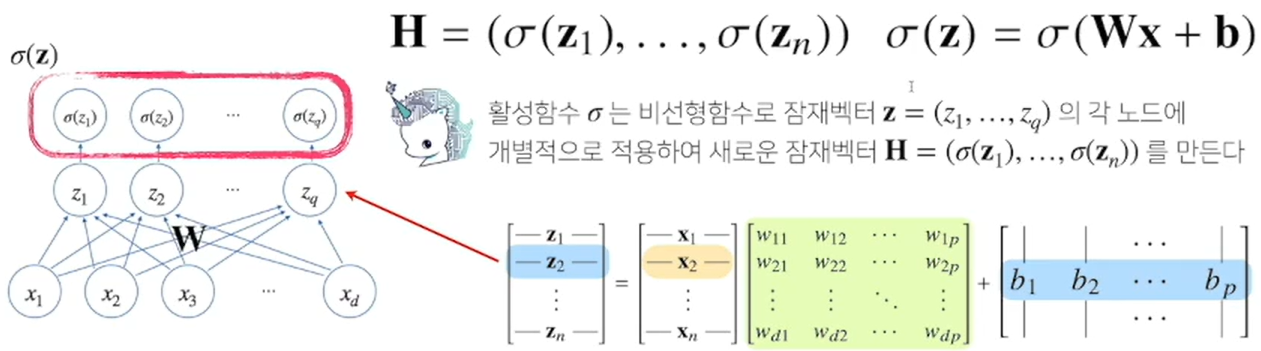
활성함수란 무엇인가??
- 실수값(R)을 입력받아 다시 실수를 출력하는 비선형nonlinear함수로서, DL에서 굉장히 중요한 함수.
- 활성함수를 쓰지 않으면 DL은 linear model과 전혀 차이가 없다.
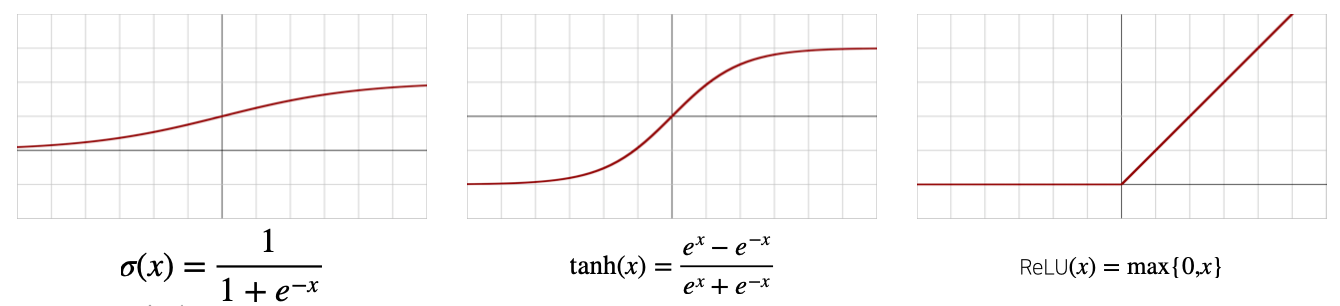
- 보통 많이 쓰이는 활성함수는 시그모이드sigmoid 함수나 tanh함수지만, DL에선 ReLU 함수를 많이 사용한다(softmax도 활성함수의 일종)
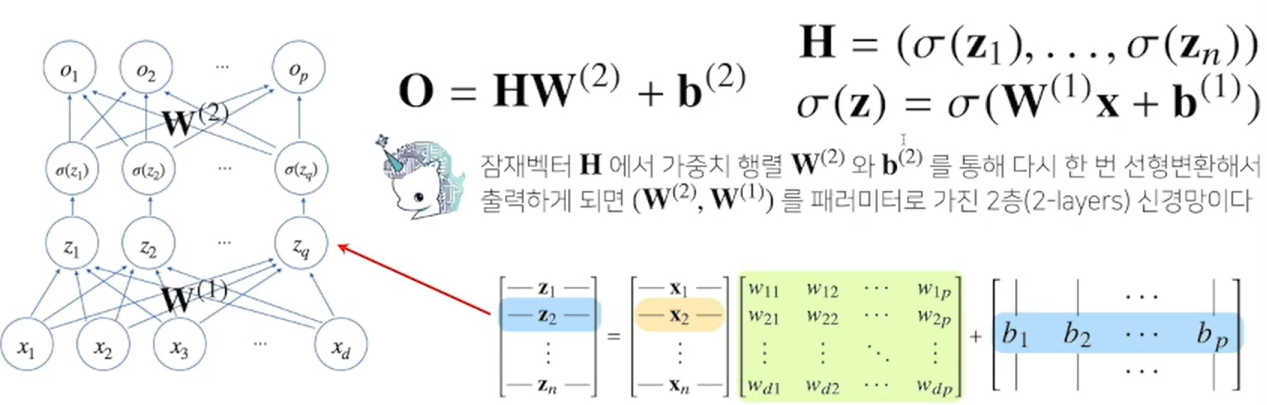
Two-Layer NN(Nerual Network)
- 선형모델에 x를 넣어 z라는 값을 얻고,
- 활성함수 sigma에 z를 넣어 잠재벡터 H(뉴런)를 얻음.
- 이 H를 다시 input으로 사용하는 선형모델을 고려해 볼 수 있다.
- 이렇듯, 선형모델을 2개 사용하는 신경망을 Two-layer Neural Network라 한다.
MLP(Multi Layer Perceptron)
1) 다층 퍼셉트론은, 신경망이 여러 층 합성된 함수.
2) DL의 가장 기본적인 모델.
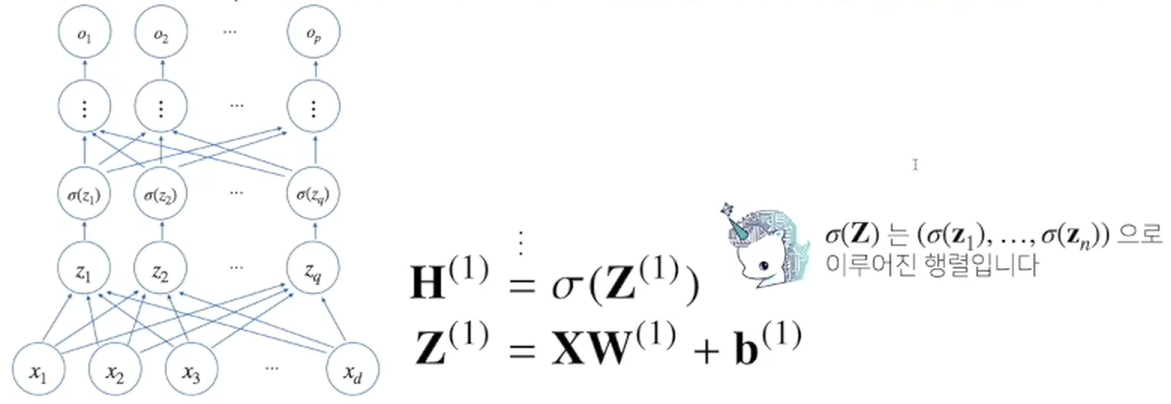
3) MLP의 파라미터는 L개의 가중치 행렬 W(1), W(2), ... , W(L)과 L개의 절편 b(1), b(2), ... , b(L)로 이루어져 있다.
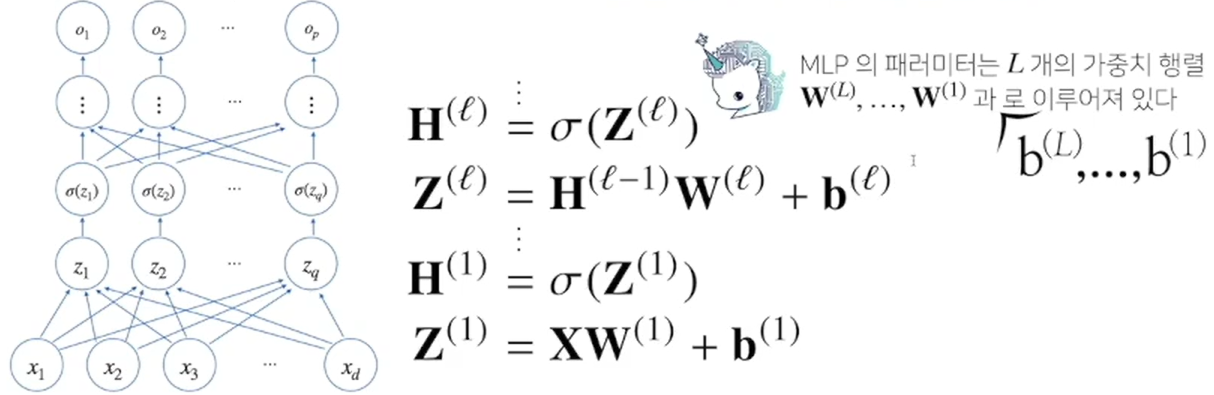
4) 이렇게 순차적인 l = 1, 2, 3, ... , L개의 신경망 계산을 통해 최종적으로 O라는 행렬을 얻음. 이런 순차적인 반 계산 방식을 순전파forward propagation 방식이라 부른다.
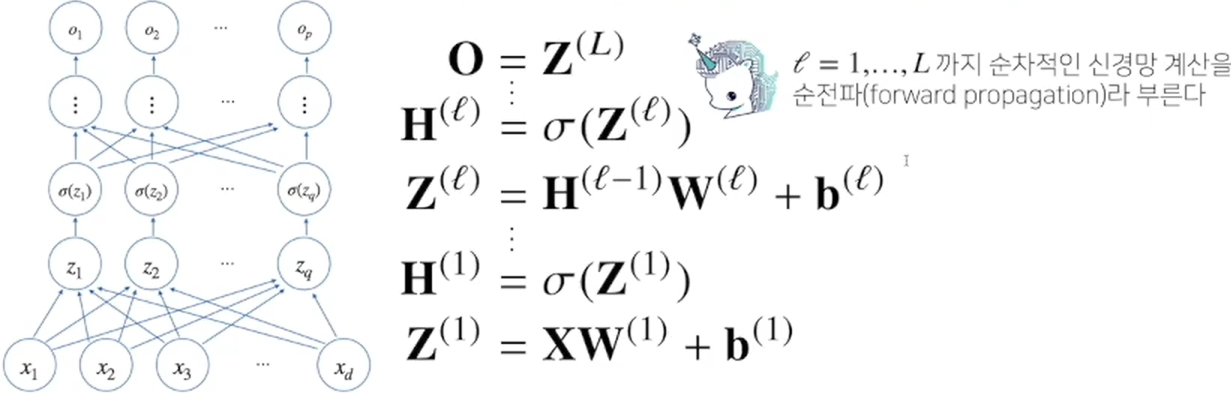
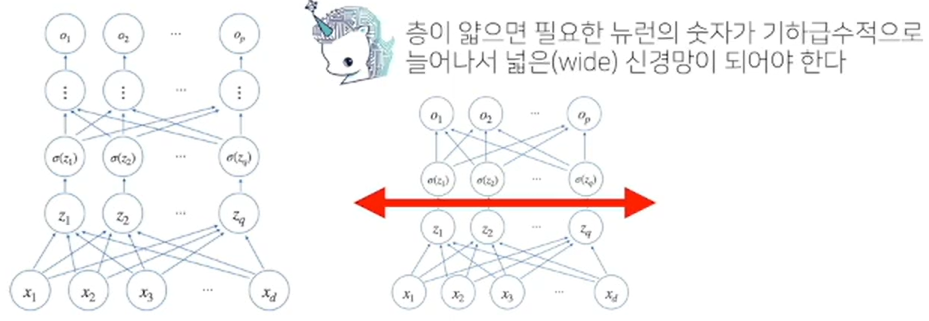
DL에서는 왜 여러 층을 사용하는가?
1) 이론상, 2층 신경망으로도 연속함수 근사 가능(universal approximation theorem)
2) 하지만 층을 여러 개 사용할수록, 목적함수를 근사하는 데에 뉴런이 적게 필요하다
=> 적은 수의 파라미터로도 복잡한 함수 표현 가능
=> 효율적인 학습 가능. 그러나, 최적화와는 다른 문제임. 층이 깊어질 수록 최적화는 어려워진다.
DL 학습원리 : 역전파 알고리즘backpropagation
1) DL은 역전파 알고리즘을 사용해서 각 층에 사용된 파라미터(가중치W, 절편b)를 학습한다
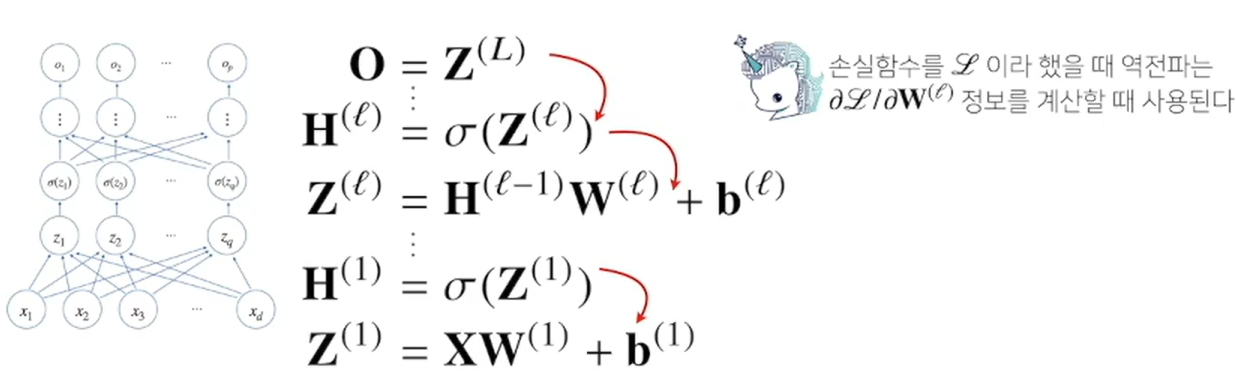
2) 경사하강법을 사용해 학습을 진행하는데, 각 가중치의 gradient vector를 계산해서 적용한다.
각 층 parameter의 gradient vector는 윗층부터 역순으로 계산한다.
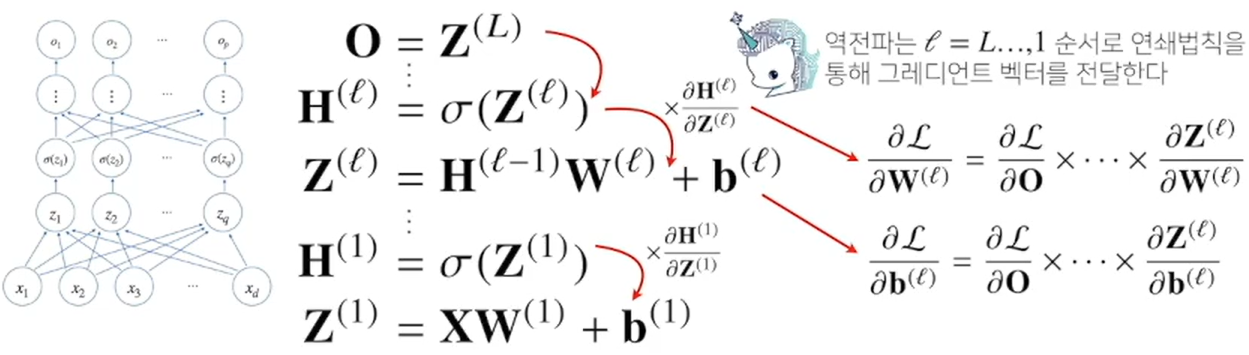
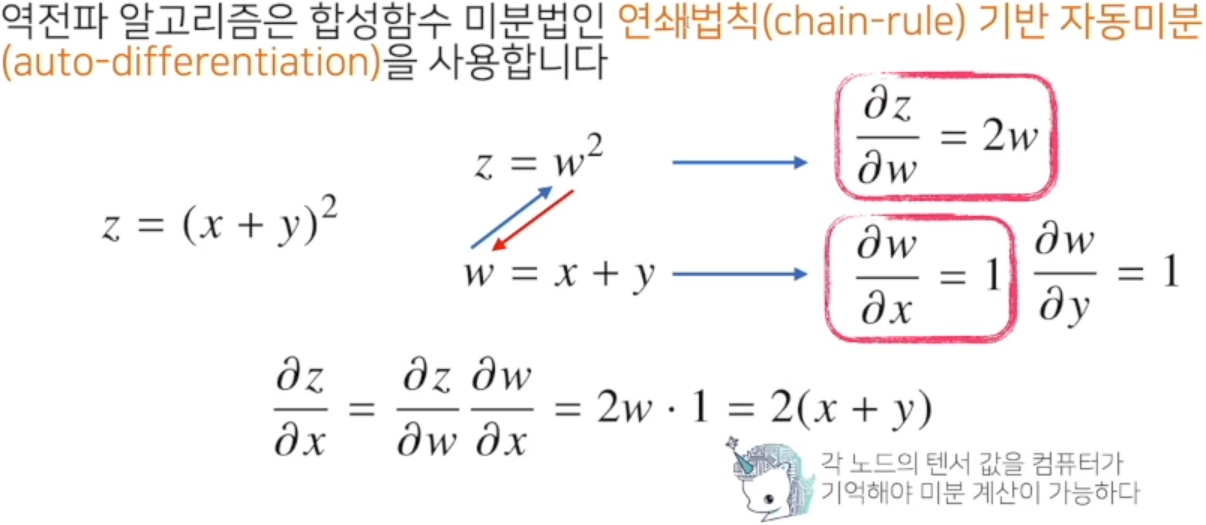
역전파 알고리즘 원리
예 : 2층 신경망의 경우...
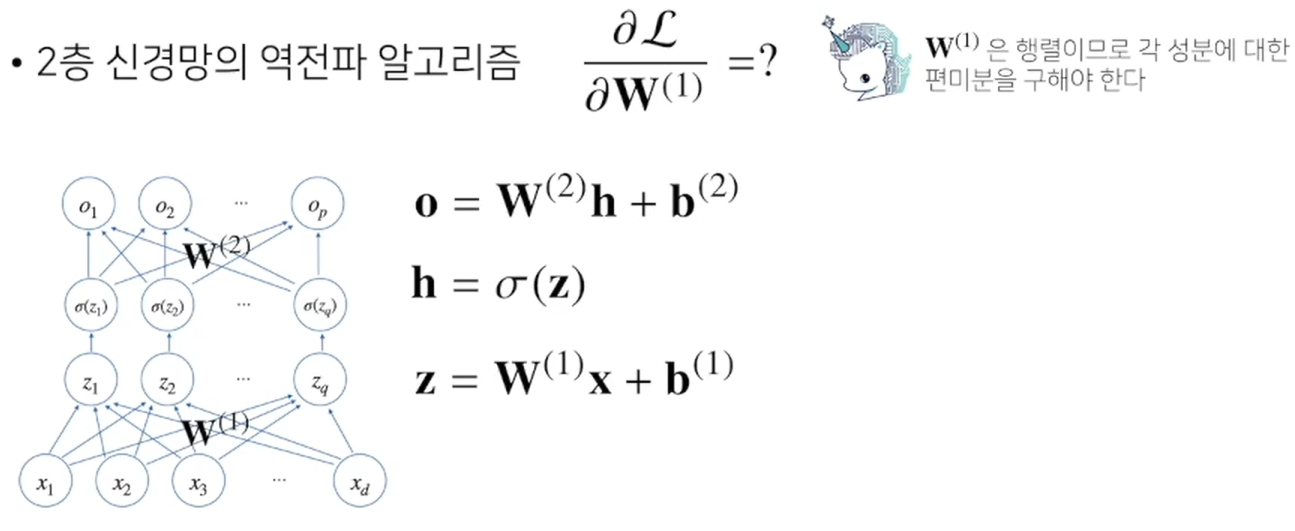
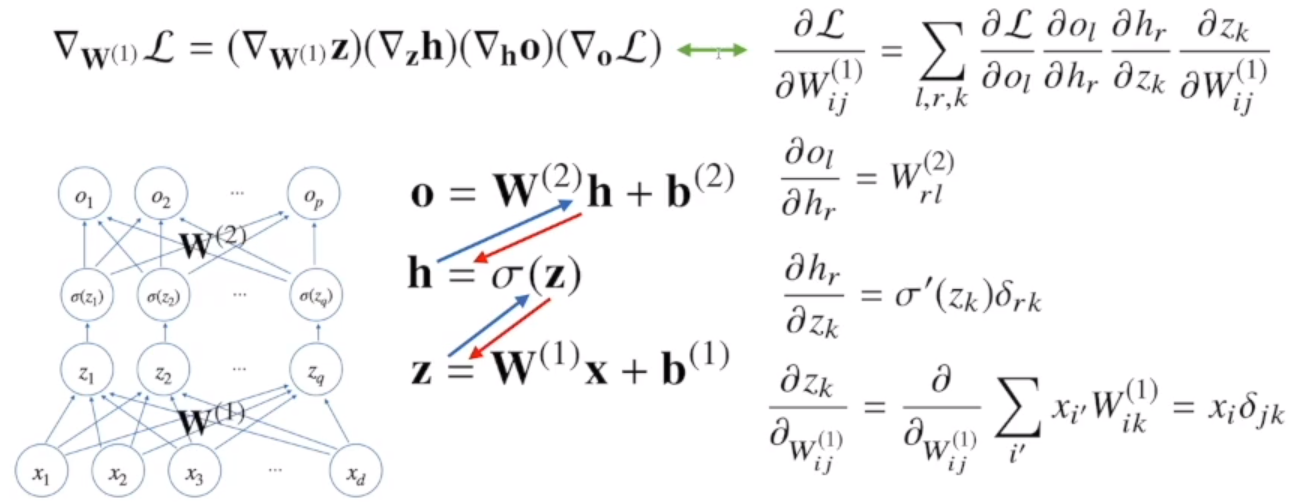
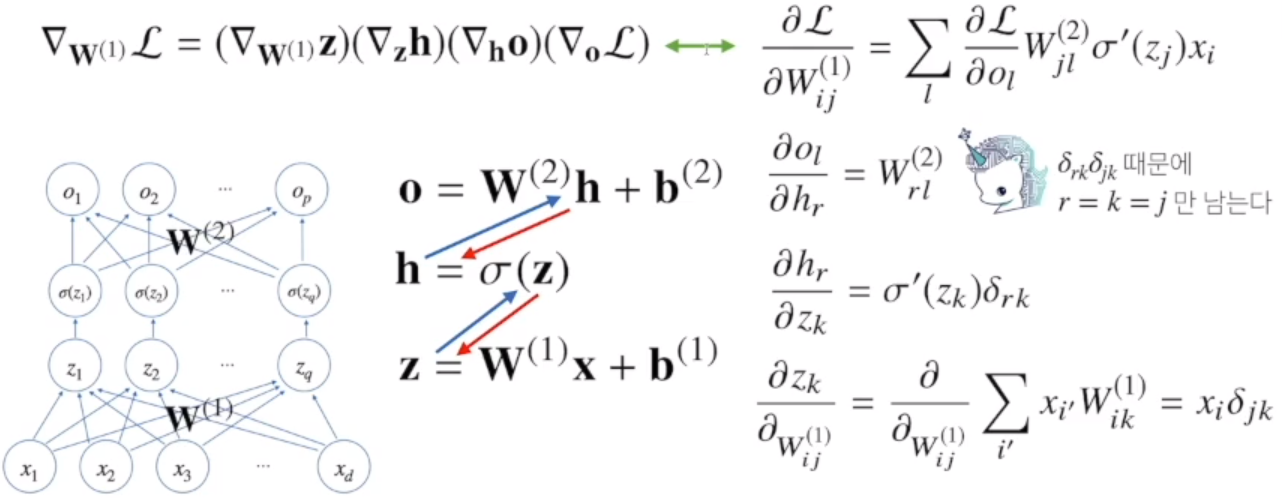
'STUDY > 부스트코스 - AI 엔지니어 기초 다지기' 카테고리의 다른 글
| [AI 엔지니어 기초 다지기] 14일차 (2) | 2024.02.07 |
|---|---|
| [AI 엔지니어 기초 다지기] 13일차 (0) | 2024.02.05 |
| [AI 엔지니어 기초 다지기] 11일차 (0) | 2024.01.30 |
| [AI 엔지니어 기초 다지기] 10일차 (0) | 2024.01.29 |
| [AI 엔지니어 기초 다지기] 9일차 (2) | 2024.01.25 |



