[24.02.15]
5주차 22차시 - 최적화(1)
최적화Optimization 기본 용어들
1. 일반화Generalization
1) 학습된 모델이 다른 새로운 데이터에 관해서도 잘 작동하도록 하는 것(How well the learned model will behave on unseen data). 학습 Iteratiion이 늘어남으로 인해 무조건 training error가 낮아진다고 해서 test error도 낮아진다는 보장이 없기 때문.
2) Generalization gap : 학습 데이터와 테스트 데이터의 에러 차이(성능차이). 이를 Generalization performance라고도 한다.

2. Underfitting vs Overfitting
1) 학습 데이터에 대해서는 잘 동작하지만(성능이 좋지만) 검증 데이터에 대해서는 그렇지 못한 것을 Overfitting되었다 라고 표현한다. 학습 데이터에 너무 과하게 fit 되어서(Over fitted) 검증 데이터에 대해서 성능이 나오지 않는 것을 의미한다.
2) 그 반대의 경우를 Underfitting이라 한다. 학습 데이터에 대해서 너무 부족하게 fit 되어서(Under fitted) 성능이 나오지 않는 경우.

3. Cross validation(K-fold validation)
1) 데이터를 train data와 validation data를 나눠서 모델에 적용하는 테크닉이다.
2) 단순히 이를 50:50으로 나누는 것보다는 k-fold validation처럼 데이터를 k개로 나누어서 k−1개는 train data로, 나머지 1개는 validation data로 설정할 수 있다.
3) Cross-validation을 해서 최적의 hyperparameter set을 찾고, 구한 최적의 hyperparameter를 고정하여 모든 데이터 셋을 다 학습시키는 게 유리하다.
4) test data는 어떤 방법으로든 모델의 학습에 사용되어서는 안 된다. 치팅임.
5) 많은 iteration을 필요로 하기 때문에, 데이터 셋이 작을 때 그 효과가 더 크다. 분류 모델을 만들고자 하는 경우, label 간 동일한 비율을 갖는 k-folds들을 추출하는 stratified k-fold를 사용하기도 한다. (label 간 데이터의 양이 불균형할 때 효과적)

4. Bias and Variance
1) Bias : 예측값과 정답값의 차이. 정답에 가까울수록 bias가 낮다고 말한다.
2) Variance : 예측값들끼리의 차이. input을 넣었을 때 output들이 얼마나 일관적인가. 일관적일수록 variance가 낮다고 말한다.
3) 보통 Low Variance인 상태의 모델을 성능이 좋은 모델이라고 한다. 정답과 거리가 멀어도 해당 모델의 bias를 ship-to 하면 되기 때문.

5. Bias and Variance Tradeoff


Cost를 최소화하는 건 세 가지 부분으로 나뉠 수 있다.
bias가 높아지면 variance가 낮아질 거이고, variance가 높아지면 bias가 낮아진다.
=> 학습 데이터에 noise가 있는 경우 Neural Network 모델에서 bias와 variance를 둘 다 낮추는 것은 어렵다. (편향-분산 트레이드오프)
6. Bootstrapping
- 통계학적 정의는 'any test or metric that uses random sampling with replacement'로, 무작위 복원 추출을 사용하는 모든 계측이나 시험을 말한다. 기계학습에서 사용하는 대표적인 기법으로는 Bagging과 Boosting이 있다.
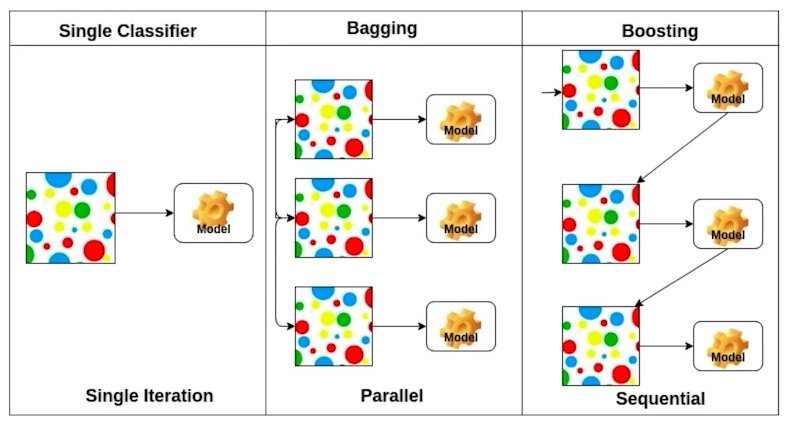
7. Bagging and Bosoting
1) Bagging (Bootstrap AGGregatING)
훈련용 데이터로부터 같은 크기의 표본을 여러 번 단순 반복추출을 통해 만들고, 이를 통해 학습시킨 여러 개의 모델의 결과 값을 voting을 통해 결합하여 최종 결과를 산출하는 방법이다. 랜덤 포레스트(Random Forest)가 이를 활용한 대표적인 예이며, 복원 추출로 인해 특정 데이터가 중복 추출되거나 추출되지 않을 수 있다는 단점이 있다.
2) Boosting
Bootstrap 표본을 통해 n번의 반복학습 및 모델 설계를 하되, (분류에 사용시) 오분류된 학습 데이터를 다음 모델 빌드 시 학습 튜플로 선택할 가능성을 높여 오류를 보완하는 방법이다. n번의 시행에서 이전 시행의 학습 및 테스트가 다음 시행에 영향을 미치며, 과도한 횟수로 반복 학습을 진행할 경우 과적합 문제가 발생할 수 있어, early stopping 기법을 사용하기도 한다. xgboost의 XGBClassifier, lightgbm의 LGBMClassifier가 대표적 예이다.
둘 다 결정트리 기반의 알고리즘으로, 부스팅 기법을 사용해 좋은 성능을 보인다.
경사하강법Gradient Descent Methids

Batch-size matters
배치 사이즈를 어떻게 결정 할 것인가?
일반적으로 모델을 학습시킬 때 전체 데이터에 대해서 한 번에 학습을 진행하는 것이 아니라 n개의 조각으로 전체의 데이터를 분할 해 여러 번에 걸쳐 학습 및 backpropagation을 진행하게 되는데, 이때 각 n개의 조각이 갖는 데이터의 수가 batch_size이다. 주로 연산 효율을 위해 2의 거듭제곱 단위인 32, 64, 128등을 사용하며, 각 조각들을 mini batch라 칭한다.
이러한 mini batch들을 사용하는 이유로는 gpu 등의 device의 메모리 한계, 모델 성능의 degredation 방지 등이 있다. 실제로 너무 큰 사이즈의 batch를 사용하는 경우 물리적으로 out of memory 문제에 마주칠 가능성도 높지만, 더 작은 배치 사이즈를 사용했을 때보다 generalization이 잘 되지 않을 가능성이 높다고 한다. 그렇다고 배치사이즈를 1로 설정한다면 연산을 해야하는 횟수가 너무 많아져 학습 시간이 지나치게 길어질 가능성이 있으니, 각 상황에 맞는 적절한 배치 사이즈를 찾아내는 것이 중요하다.
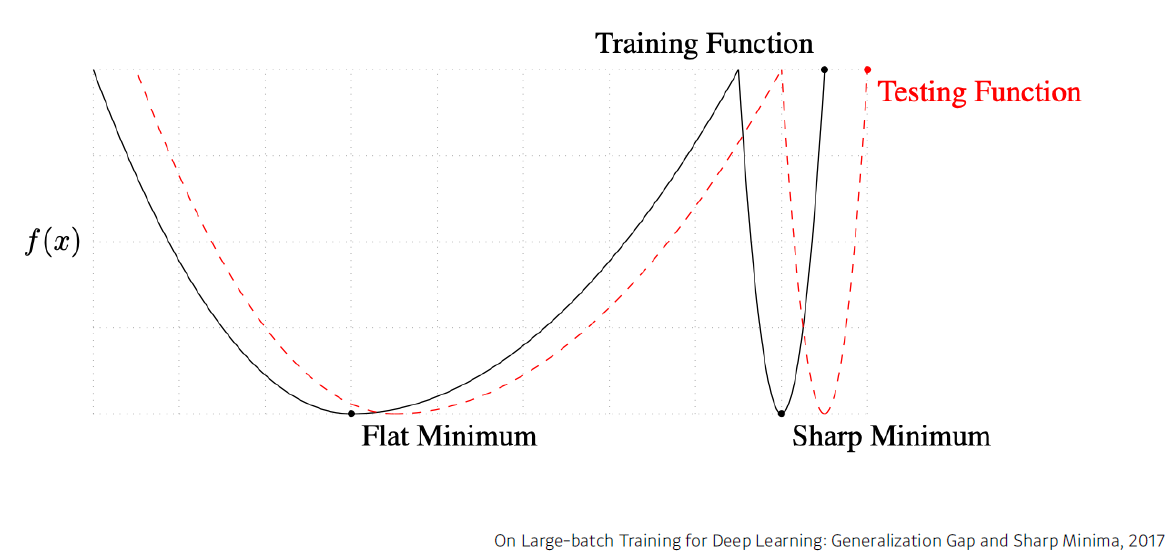
2017년 발표된 논문에서 배치 사이즈를 작게 가져갈수록 Flat minimum을 가질 확률이 높으며, 이는 곧 generalization이 잘 될 확률이 더 높다는 것을 밝혔다.
'STUDY > 부스트코스 - AI 엔지니어 기초 다지기' 카테고리의 다른 글
| [AI 엔지니어 기초 다지기] 19일차 (0) | 2024.02.16 |
|---|---|
| [AI 엔지니어 기초 다지기] 17일차 (2) | 2024.02.14 |
| [AI 엔지니어 기초 다지기] 16일차 (0) | 2024.02.13 |
| [AI 엔지니어 기초 다지기] 15일차 (0) | 2024.02.09 |
| [AI 엔지니어 기초 다지기] 14일차 (2) | 2024.02.07 |



