[24.02.16]
5주차 23차시 - 최적화(2)
Regularization
: 학습에 규제를 걸어서 데이터 학습이 잘 되지 않도록 하는 것. 그렇게 함으로써 모델 혹은 방법론이 학습데이터에만 잘 동작하는 것이 아니라 테스트 데이터, 혹은 그 외의 데이터에 대해서도 잘 동작하도록 하는 것.
즉, Overfitting을 방지하는 것이 목적이다.
아래와 같이 다양한 방법이 있다.
1. Early Stopping
- Test data가 아닌, 그 외의 데이터로 validation data set을 구축하고 해당 데이터셋에 대해서 error가 더 이상 줄어들지 않을 때에 학습을 종료하는 것. 말 그대로 조기 종료하는 것이다. n번의 epoch 학습 동안 모델 성능이 나아지지 않는다면 학습을 종료하는 방식으로 설정해줄 수 있다.

2. Parameter Norm Penalty
- Neural Network의 parameter가 너무 커지지 않도록 하는 것. 각 weight들이 너무 커지지 않게 제한을 두는 것을 말한다. 이는 함수에 smoothness를 더해줄 수 있고, 더 smooth한 함수가 보다 잘 generalize 될 것이라는 가정을 바탕에 둔다. Weight Decay라고도 하며, Ridge Regression, Lasso Regression 등이 이를 활용한 예이다.
3. Data Augmentation
- More Data are always welcomed.
주어진 데이터를, label이 바뀌지 않는 한도 내에 어떤 식으로든 늘리는 것을 말한다. 대표적으로 이미지의 화질을 바꾸거나 회전, 확대축소, 좌우 반전시키는 등의 변화를 준 데이터들을 학습에 활용하는 것이 그 예이며 이는 Label Preserving Augmentation이라 부르기도 한다.
4. Noise Robustness
- input data와 nerual network의 weight 의도적으로 noise를 집어넣는 것. 이렇게 해 주면 성능이 더 좋아진다는 실험 결과가 있다.Augmentation의 일종이다.
5. Label Smoothing
- 학습 데이터 2개를 뽑아 섞어준 후, 해당 데이터를 학습에 추가로 활용하는 것. 이미지 detecting시에는 decision boundary를 보다 smooth하게 만들어주는 효과가 있다. 섞는 방법에 따라 Mixup, Cutout, CutMix 등의 방법이 있다. 왜 잘되는지 설명되어있다기보단, 실험적으로 성능이 굉장히 좋아진다는 것이 알려져 있어서 활용하는 편이다.
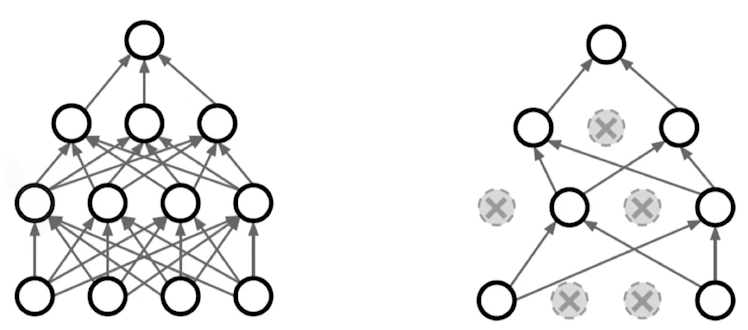
6. Dropout
- 학습을 진행할 때 random하게 neural network 특정 노드의 weight들을 0으로 설정한다. ratio 값을 지정해줌으로써 특정 비율의 노드들을 삭제한다. 이 역시 수학적으로 증명되었다기보단 실험적으로 증명된 방법이다.
7. Batch Normalization
- 특정 레이어가 가지는 weights들의 통계적 분포를 표준정규화한다. 즉, weights들의 확률분포의 평균을 0, 분산을 1로 만든다. 레이어가 깊게 쌓인 경우에 그 효과가 크다고 한다. 이 역시 해석보단 실험적으로 증명되었다.

'STUDY > 부스트코스 - AI 엔지니어 기초 다지기' 카테고리의 다른 글
| [AI 엔지니어 기초 다지기] 18일차 (0) | 2024.02.15 |
|---|---|
| [AI 엔지니어 기초 다지기] 17일차 (2) | 2024.02.14 |
| [AI 엔지니어 기초 다지기] 16일차 (0) | 2024.02.13 |
| [AI 엔지니어 기초 다지기] 15일차 (0) | 2024.02.09 |
| [AI 엔지니어 기초 다지기] 14일차 (2) | 2024.02.07 |



