[24.01.23]
2주차 9차시 - 피처 중요도
1. 피처 중요도Feature Importance란?
- 타겟 변수를 예측하는데에 사용된 각각의 feature들이 예측에 얼마나 유용하게 사용되었는지를, 각 feature들에 점수로 할당해서 중요도를 측정하는 방법. 2가지 방법이 있다.
1.1 Model specific vs Model agnostic : ML모델 자체에서 중요도를 계산하는 방법을 Model specific, 모델 학습 후에 모델의 중요도 계산 기능이 아닌 다른 방법으로 중요도를 계산하는 방법을 Model agnistic이라 한다.
2. Boosting Tree Feature Importance( Model specific )
2.1 LightGBM Feature Importance
- LightGBM은 해당 모델에서 피처 중요도를 계산할 수 있는, feature_importance(importance_type) 라는 함수를 제공한다.
LIghtGBM에서 사용할 수 있는 importance type에는 split이나 gain 이 있고, 기본값은 split이다
1) split : numbers of times the feature is used in a model. 해당 feature가 모델에서 얼마나 많은 분기(split)를 나누는 데에 사용되었는지를 나타낸 수. 쉽게 말해 사용된 횟수라고 이해하면 된다. 즉 높을 수록 중요한 feature다.
2) gain : total gains of splits which use the feature. 해당 feature가 얻은 총 gain을 나타낸다. 이 역시 높을 수록 중요한 feature다.
** 잠깐! gain이란 무엇인가?
여기서의 gain이란, 정보 이득Information Gain을 말한다.
정보 이득(Information Gain)이란, 결정 트리(Decision Tree)와 같은 트리 기반 알고리즘에서 노드(node)의 분기(split)를 결정하는 데 사용되는 중요한 개념이다. 이는 분기 전과 후의 엔트로피 차이를 기반으로 계산되며, tree는 이 차이(=gain)가 최대화 되는 방향으로 분기하게 된다.
그렇담, 이번엔 엔트로피란건 무엇인가?
엔트로피(Entropy)는 데이터의 불순도를 의미한다. 한 노드에 여러 클래스의 데이터가 섞여 있을수록 엔트로피가 높다. 반대로, 한 노드가 특정 클래스의 데이터만을 가지고 있다면 엔트로피는 0이 된다.
정리하자면,
정보 이득은 분기 전의 엔트로피와 분기 후의 엔트로피를 비교하여, 분기로 인해 얼마나 많은 '불확실성'이 줄어들었는지를 측정하는 지표다. 즉, 어떤 특징을 기준으로 데이터를 분기했을 때, 그 결과로 얼마나 많은 정보를 '이득'하게 되었는지를 수치화한 것이라고 볼 수 있다. **
2.1 XGBoost Feature Importance
- XGBoost는 해당 모델에서 피처 중요도를 계산할 수 있는, get_score(importance_type) 라는 함수를 제공한다. 사용 가능한 Importance type은 아래와 같다. 기본값은 weight이다
1) weight : the number of times a feature is used to split the data across all trees. 즉, 해당 feature가 얼마나 많이 사용되었는지를 나타내는 지표이다. LightGBM의 split과 흡사하다.
2) gain : the average gain across all splits the feature is used in. gain을 나타내는 지표인데, LightGBM의 gain과는 달리 평균 gain을 나타낸다.
3) cover : the average coverage across all splits the feature is used in. 해당 feature의 coverage의 평균값.
4) total gain / total cover : total gain / total cover
** coverage란, 짧게 설명하면 해당 feature가 커버한(관여한, 분리해낸) 샘플 데이터셋의 개수다. 예를 들어 4개의 feature를 가진 100개의 샘플을 decision tree 1, 2, 3 에 훈련시켰다고 하자. 그리고 feature 1이 tree1에서 10개의 샘플을, tree 2에서 5개의 샘플을, tree 3에서 2개의 샘플을 구분해냈다고 할 때, feature1의 coverage는 17이 된다. **
2.2 CatBoost Feature Importance
- CatBoost는 해당 모델에서 피처 중요도를 계산할 수 있는, get_feature_importance(type) 라는 함수를 제공한다. 사용 가능한 type은 아래와 같다. 기본값은 FeatureImportance이다.
1) FeatureImportance : Equal to PredictionValuesChange for non-ranking metrics and LossFunctionChange for ranking metrics.
각 feature가 모델의 예측을 생성하는 데 얼마나 중요한 역할을 하는지를 측정한다. 이 방법에는 'PredictionValuesChange'와 'LossFunctionChange' 두 가지 방식이 있다. 'PredictionValuesChange'는 각 특징의 값이 변경될 때 예측 값이 얼마나 변하는지를 측정하고, 'LossFunctionChange'는 각 특징의 값이 변경될 때 손실 함수가 얼마나 변하는지를 측정한다.
2) ShapValues : A vector with contributions of each feature to the prediction for every input object and the expected value of the model prediction for the object.
SHapley Additive exPlanations(SHAP)을 사용하여 각 feature가 예측에 미치는 기여를 측정한다. SHAP 값은 각 특징이 예측에 미치는 평균적인 기여도를 나타내므로, 이를 통해 각 특징의 중요도를 해석할 수 있다.
3) Interaction : The value of the feature interaction strength for each pair of features.
feature 간의 상호작용이 예측에 미치는 영향을 측정한다. 이는 feature 간의 상호작용이 모델의 예측을 얼마나 개선하는지를 측정하는 것으로, 이를 통해 feature 간의 상호작용의 중요도를 해석할 수 있다.
4) PredictionDiff : A vector with contributions of each feature to the RawFormulaVal difference for each pair of objects.
각 feature 값이 변경될 때 예측 값이 얼마나 변하는지를 측정한다. 이 방법은 'FeatureImportance'의 'PredictionValuesChange' 방식과 유사하지만, 'PredictionDiff'는 각 특징의 값을 변경했을 때 예측 값의 변화를 개별 샘플 수준에서 측정한다.
피처 중요도는 아래의 그래프와 같이, 직관적으로 어떤 feature가 중요하게 쓰였는지를 확인하는 데에 사용된다.

3. Permutation Feature Importance(Model agnostic)
: feature의 값들을 무작위로 섞은 후, 모델의 error를 측정한다. error가 크게 나온다면? 해당 feature가 중요한 feature인 것이고, 작게 나온다면? 모델 성능과는 별 관련 없는, 덜 중요한 feature인 것. 장점은, 어떤 모델에든 사용할 수 있는 방법이라는 것! 이런 장점 덕인지, 요새 많이 쓰이는 feature importance 측정 기법이다.
scikit-learn에서 제공하고 있으므로, 편하게 사용할 수 있다.
4. Feature Selection
: 피처 선택. ML 모델에서 쓸 피처 중 유용한 것과 유용하지 않은 것을 가려내어 선택하는 과정. 모델의 복잡도를 낮추어 Overfitting 방지 및 모델의 속도 향상 등의 효과를 기대할 수 있음.
4.1 Filter Method
: 통계적인 측정 방법을 사용해서 feature간 상관관계를 알아내어 쓸만한, 쓸만하지 않은 feature를 가려내는 방식. 그러나, 이 상관관계란 것이 항상 모델의 성능에 좋은 영향을 끼치는 것은 아니기 때문에 이 방법이 가장 좋은 방법은 아니다. 하지만 가장 간단한 방법. 그렇기 때문에 보통 전처리 하는 데에 주로 쓰이는 방법.
ex) 1. corr()을 통해 feature간 corr를 계산함 => corr이 1에 가까운 feature 쌍은, 두 feature가 거의 같은 역할을 하고 있다고 봐도 되기 때문에 둘 중 하나를 제거.
2. feature에 있는 data들의 분산variance 계산. => variance가 굉장히 작다면? 해당 feature의 데이터들은 거의 다 비슷비슷한 데이터라는 의미 => 해당 feature는 target변수를 예측하는 데에 중요하게 쓰이지 않을 가능성이 높음.
4.2 Wrapper Method
: 예측 모델을 사용해서 feature의 subset을 계속해서 테스트해서 어떤 feature가 중요한지 알아내는 방식
기존 데이터에서 성능을 측정할 수 있는 holdout 데이터셋을 따로 두어서 validation 성능 측정하는 방법이 필요함.
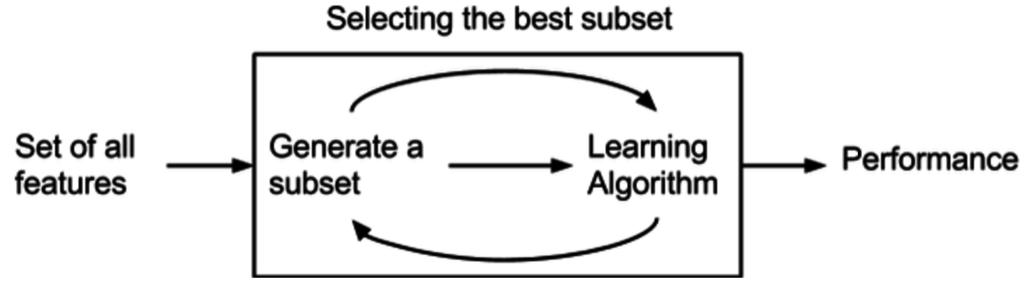
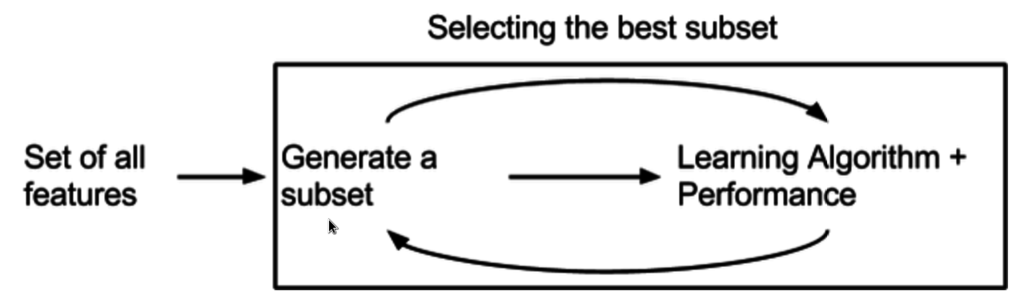
4.3 Embedded Method
: 위 2가지 방식의 장점을 결합한 방식. 학습 알고리즘 자체에 feature selection이 들어가 있는 것을 말한다.
'STUDY > 부스트코스 - AI 엔지니어 기초 다지기' 카테고리의 다른 글
| [AI 엔지니어 기초 다지기] 9일차 (2) | 2024.01.25 |
|---|---|
| [AI 엔지니어 기초 다지기] 8일차 (0) | 2024.01.24 |
| [AI 엔지니어 기초 다지기] 6일차 (0) | 2024.01.22 |
| [AI 엔지니어 기초 다지기] 5일차 (0) | 2024.01.19 |
| [AI 엔지니어 기초 다지기] 4일차 (0) | 2024.01.18 |



