[24.01.25]
2주차 11차시 - 앙상블
1. Ensemble
: 특정한 알고리즘이 모든 문제에서 항상 제일 나은 성능을 보이지 않는다는 연구결과
=> 더 나은 모델 성능을 위해 여러 개의 알고리즘을 조합해서 사용하는 것.

1.1 Ensemble Learning
- 여러개의 Decision Tree를 결합하여 하나의 D.T보다 더 좋은 성능을 내는 ML 기법.
- 앙상블 학습의 핵심은, 여러개의 약한 분류기Weak Classifier를 결합해서 하나의 강한 분류기Strong Classifier를 만드는 것이라 할 수 있다. 마치 집단지성.

1.2 Ensemble Learning 기법
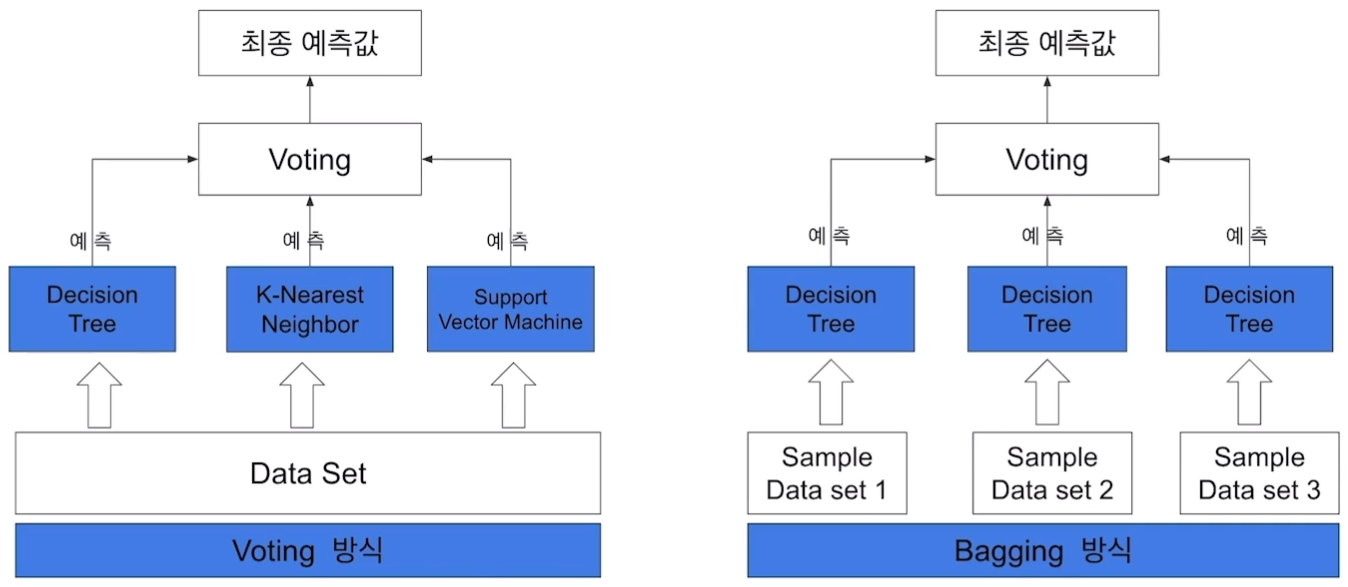
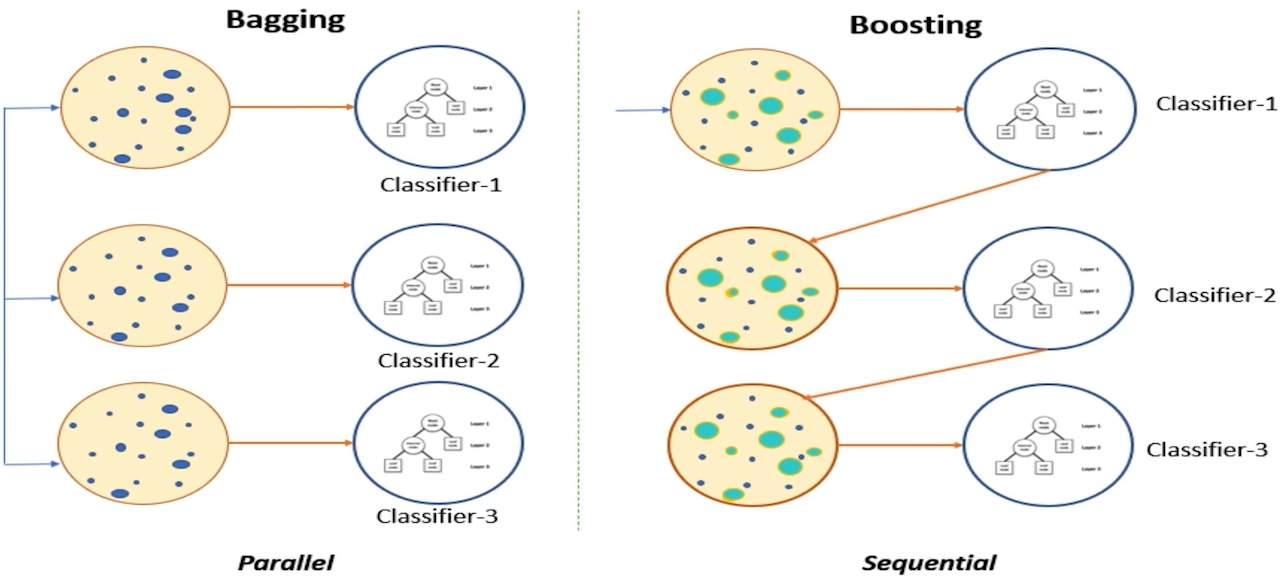
1) Bagging(Boostrap Aggregation)

- 장점 : Overfitting에 효과적이다.
- 대표 알고리즘 : Random Forest

2) Voting

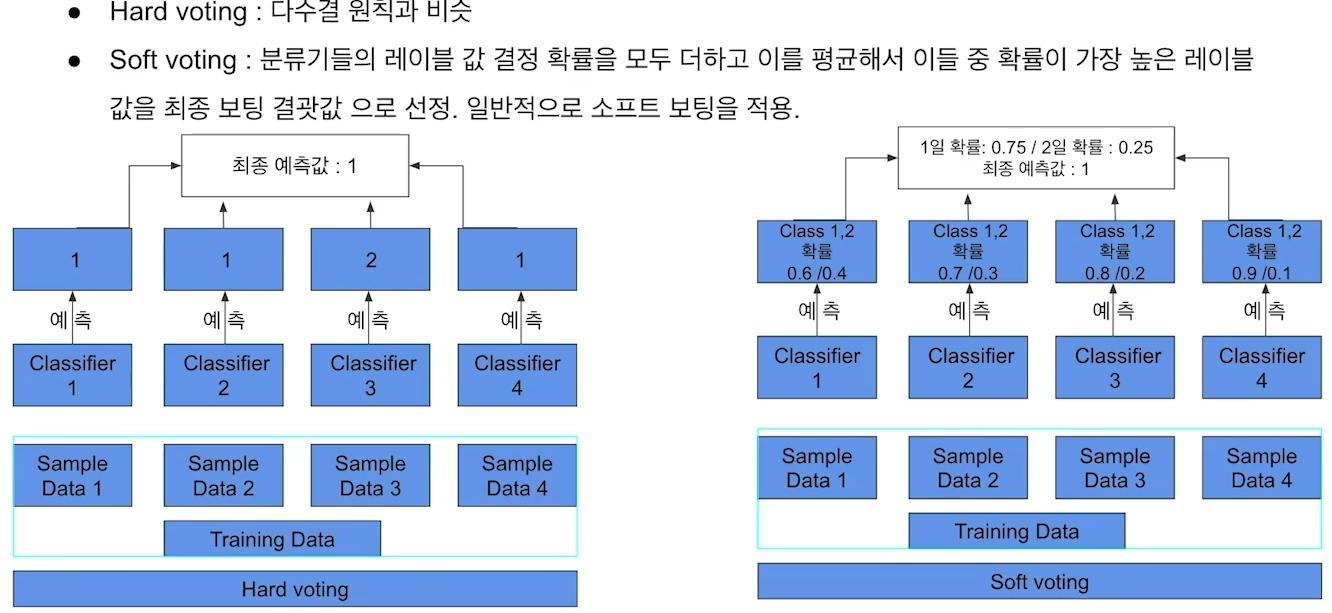
** Bagging VS Voting
3) Boosting :
여러 개의 Classifier가 순차적으로 학습 => 이전 분류기가 틀린 부분에 대해 가중치를 주고, 그 가중치를 고려한 데이터를 그 다음 분류기가 학습하고, 또 여기서 틀리게 분류한 부분에 대해 가중치를 주고, 그 가중치를 고려한 데이터를 그 다음 분류기가 학습하고...
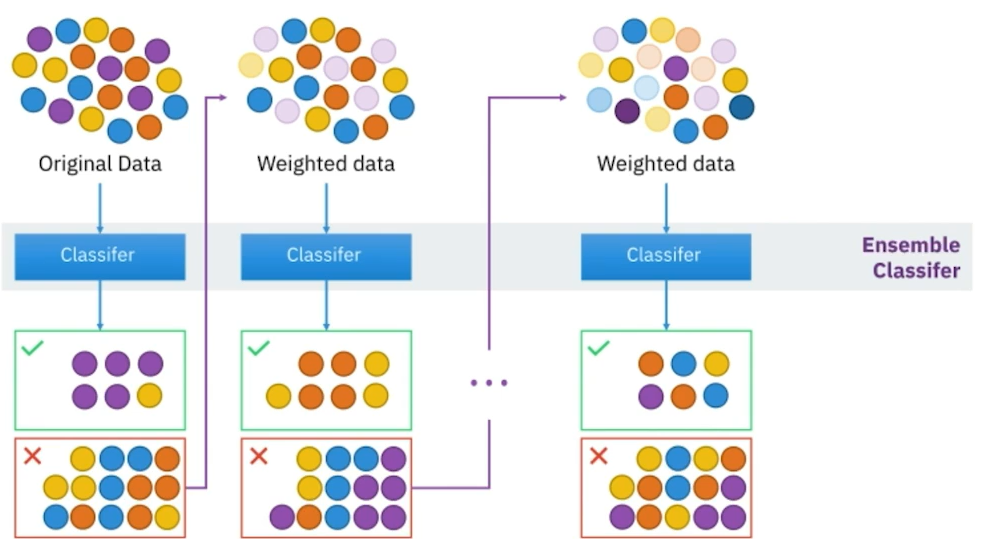
- 대표 알고리즘 : LightGBM, XGBoost, CatBoost 등.
- 특징 : 순차적으로 학습하기 때문에 속도가 느릴 수 있고, Overfitting을 주의해야 한다.
** Bagging VS Boosting
4) Stacking : 여러 모델을 활용해 각각 예측한 뒤, 예측 결과들을 결합해서 최종 예측을 만들어내는 것.
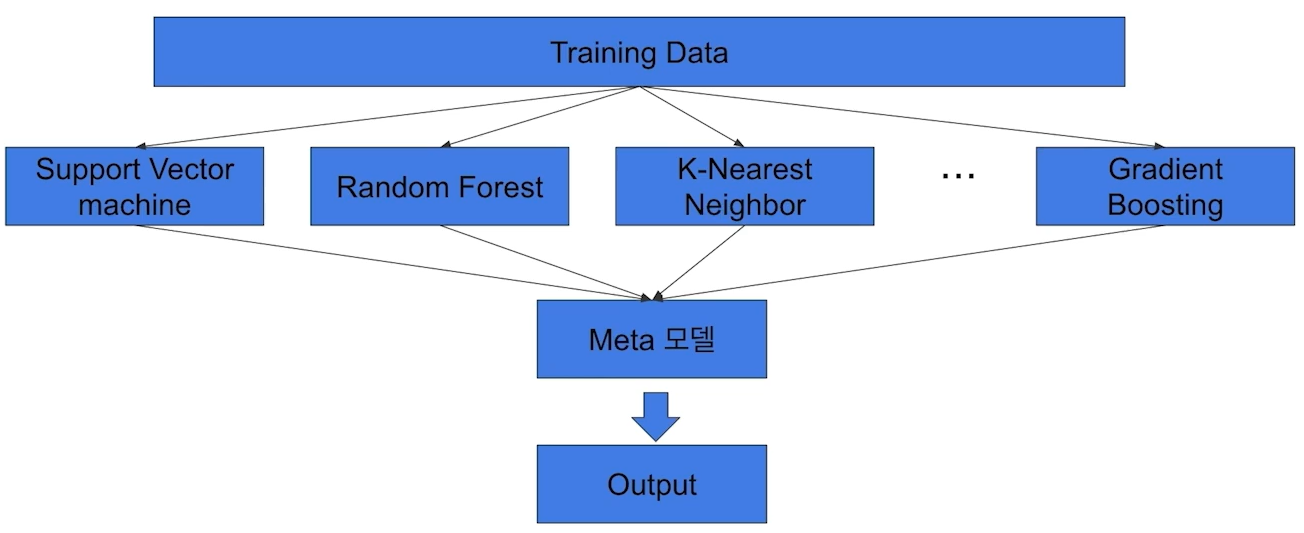
- 2종류의 모델이 필요하다.
처음에 예측을 수행할 Base model, 해당 예측값들을 취합해서 최종적으로 예측하는 Meta model.
- 성능은 우수하지만, Overfitting의 위험이 있고, 좋은 성능을 내기 위해서 굉장히 많은 모델을 조합해야 하기에 시간이 굉장히 오래 걸려서 잘 쓰이지는 않으나, 최고의 성능을 원한다면 써봄직하다.
2. Tree Algorithm
2.1 Decision Tree : Impurity(불순도)
- 하나의 노드 안에 있는 데이터가 덜 분류되어 있을수록(=많이 섞여있을수록) 불순도가 높고, 많이 분류되어 있을수록 불순도가 낮다.
- 불순도 측정 방법에는 Entropy복잡도와 Gini지니계수가 있다.
- Gini Index지니계수 : 불순도를 측정하는 지표 중 하나. 데이터의 통계적 분산 정도를 정량화해서 표현한 값이다. 낮을 수록 불순도가 낮음을 의미한다.
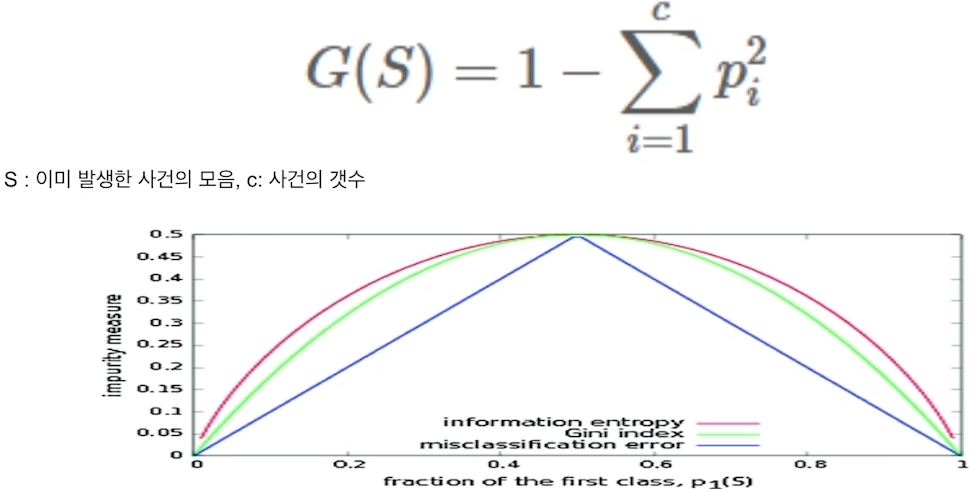
2.2 XGBoost
- Gradient Boosting의 단점을 보완하기 위해 정규화를 추가한 알고리즘. 다양한 손실함수를 Overfitting을 막는다. 학습 시간이 오래 걸린다는 단점이 있다.
2.3 LightGBM
- 학습시간이 느리고 하이퍼 파라미터가 많은 XGBoost를 단순화한 알고리즘. 다른 Boosting tree모델에 비해 대용량 데이터를 쉽게 처리할 수 있다. 단, 데이터가 적다면 Overfitting의 가능성이 높다.

2.4 Catboost
- 범주형 데이터(Category)가 많은 경우에 유용한 boosting tree 모델. 그래서 이름도 Catboost(Category boost)다.

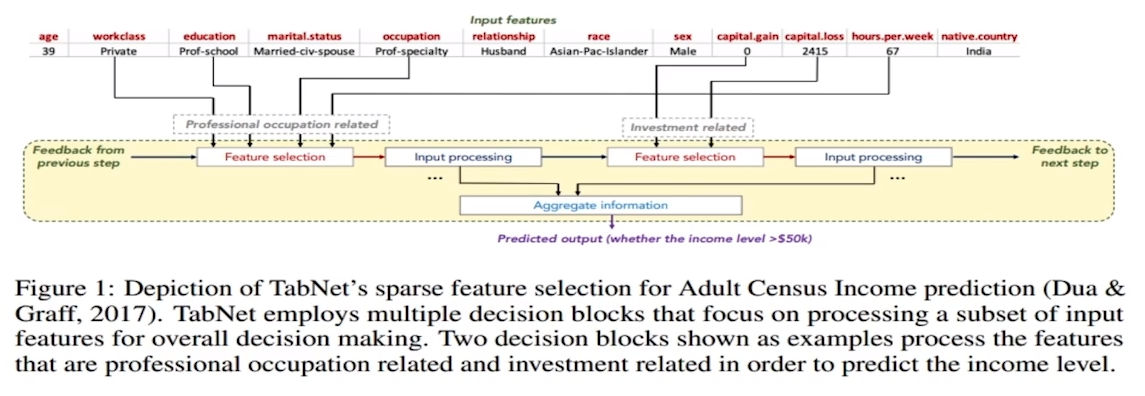
3. TabNet (DL model for Tabular Data)
- 전처리 과정 필요 없음
- 순차적 어텐션Sequentia Atention을 사용해서 각 의사결정 단계에서 추론할 특징 중 학습 능력이 가장 두드러지는 특징 사용.
- 정형 데이터에 대해서는 다른 신경망 모델이나 D.T모델에 비해 성능이 우수함
- Feature selection이 이루어지는 신경망 모델이기 때문에, 어떤 특징이 중요한지 설명 가능함
=> 설명 가능한 모델(XAI, eXplainable AI')이다
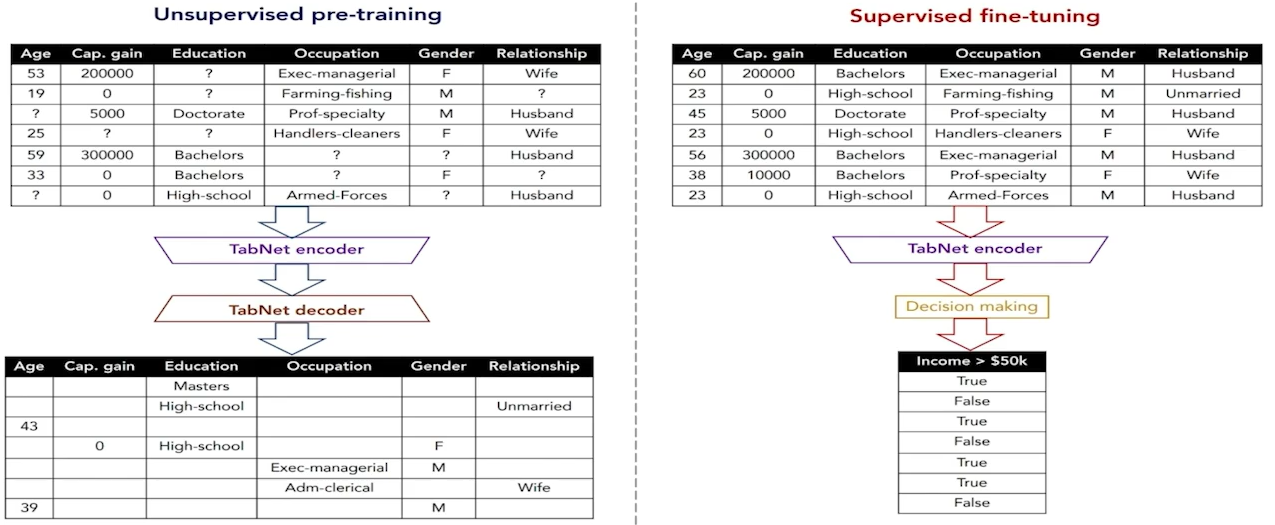
- Unsupervised pre-train 단계를 적용해서 성능이 매우 좋음.
'STUDY > 부스트코스 - AI 엔지니어 기초 다지기' 카테고리의 다른 글
| [AI 엔지니어 기초 다지기] 11일차 (0) | 2024.01.30 |
|---|---|
| [AI 엔지니어 기초 다지기] 10일차 (0) | 2024.01.29 |
| [AI 엔지니어 기초 다지기] 8일차 (0) | 2024.01.24 |
| [AI 엔지니어 기초 다지기] 7일차 (0) | 2024.01.23 |
| [AI 엔지니어 기초 다지기] 6일차 (0) | 2024.01.22 |



