내돈내산 강의 내용 정리
유데미의 '비즈니스 분석 및 Data Science를 위한 핵심 통계학 A - Z'
https://www.udemy.com/course/data-statistics/?couponCode=JUST4U02223
이전 포스팅 보러가기
[분류 전체보기] - 비즈니스 분석 및 DS를 위한 핵심 통계학_분포 - 연속 vs 불연속
비즈니스 분석 및 DS를 위한 핵심 통계학_분포 - 연속 vs 불연속
내돈내산 강의 내용 정리 유데미에서 아래 강의를 내돈주고 구매해서(할인이길래 냉큼 구매했다) 들으며, 강의 내용을 내 나름 정리해보고자 한다. 나중에 까먹었을 때 읽으면 바로바로 기억날
k-wien1589.tistory.com
분포Dstribution
분포란 무엇인가?
이전 포스팅인 연속 vs 불연속 파트에서, 분포를 다룰 때 아주 중요한 개념이다... 라는 말을 했었다. 분포? 그게 뭐죠?
우선 정의를 보자.
" 실험에서 발생 가능한 여러 결과에 대한 확률을 제공하는 수학적 함수 "
라고 한다.
보통, 분포는 확률 분포를 의미한다. 그리고, '여러 결과'는 확률 변수라는 이름으로 불린다.
즉 다시 정리해보자면,
" 확률 분포란, 실험에서 확률 변수가 여러가지 특정 값을 가질 확률을 제공하는 수학적 함수"
라고 할 수 있다.
이 정의에서 중요한 부분은, 분포란 것은 "수학적 함수"라는 것이다. 그래프, 차트 등과 관련된 것이 아니다.
자세히 살펴보자.
정의에서 말하는 실험이란 게 무엇인가? 대표적 예로는 동전 던지기가 있을 수 있다.
우리 데이터를 다시 보자면..

여기서 실험이라 함은, 이 데이터셋에서 특정 데이터 하나를 무작위로 고르는 것이라 하자. 동전 던지기와 다를 바가 없다.
Age컬럼의 데이터 중 하나를 고른다. 이 행동의 결과로 27, 38, 41, 80, ... 등의 데이터가 나올 수 있다.
=> 그러므로 이 경우, 확률분포란, Age컬럼 데이터(=확률 변수) 무작위 선택이라는 실험의 결과값으로 각 데이터들이 나올 확률을 알려주는 수학적 함수인 것이다.
연속과 불연속은, 분포를 다룰 때 아주 중요한 개념이라고 했다. 또한, 두 개념의 차이는 변수라고도 했다.
즉 연속 변수의 확률분포와 불연속 변수의 확률분포가 서로 다름을 알 수 있다.
위 데이터셋에서 불연속 변수인 Age group과 연속 변수인 잔고의 분포를 그래프로 나타내어 보면, 아마 대략 아래와 같을 것이다.
- 불연속(=이산) 확률분포
=> 무작위로 고객 한 명을 골랐을 때, 해당 고객의 Age group 데이터가 특정 값을 가질 확률
=> 예를 들어, 해당 고객의 Age group이 30~40일 확률은 30%

연속 변수인 잔고의 그래프는 어떨까?
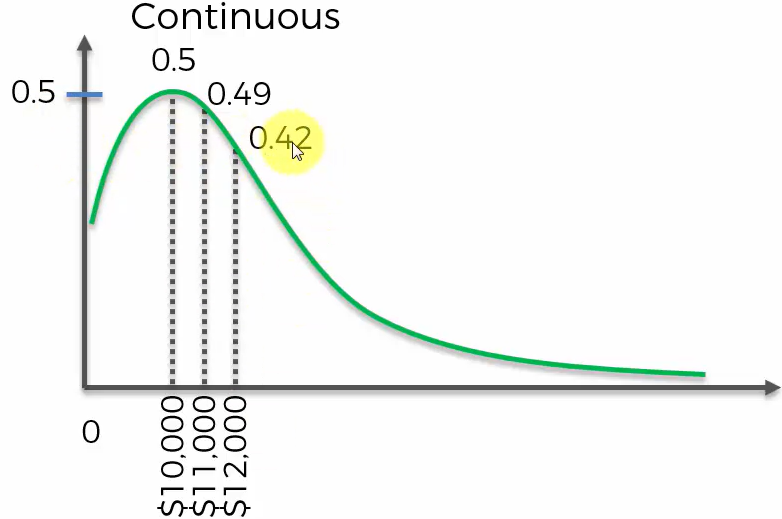
위 그래프에서 나타나는 것이, 무작위로 한 명의 고객을 골랐을 때 해당 고객의 잔고가 정확히 만 달러일 확률이 50%라는 것일까?
그렇다면, 만 천달러일 확률은 49%여야 하고 만 이천달러일 확률은 42%여야 한다.
말이 안 된다. 이미 확률이 100%를 넘어버리지 않는가.
즉 불연속 확률변수처럼 확률을 판단해서는 안 된다는걸 알 수 있다.
이 그래프에서 확률을 찾는 올바른 방법은 면적을 계산하는 것이다. 면적이 확률을 나타낸다.
그렇다면 다시 돌아가서,
- 연속 확률분포
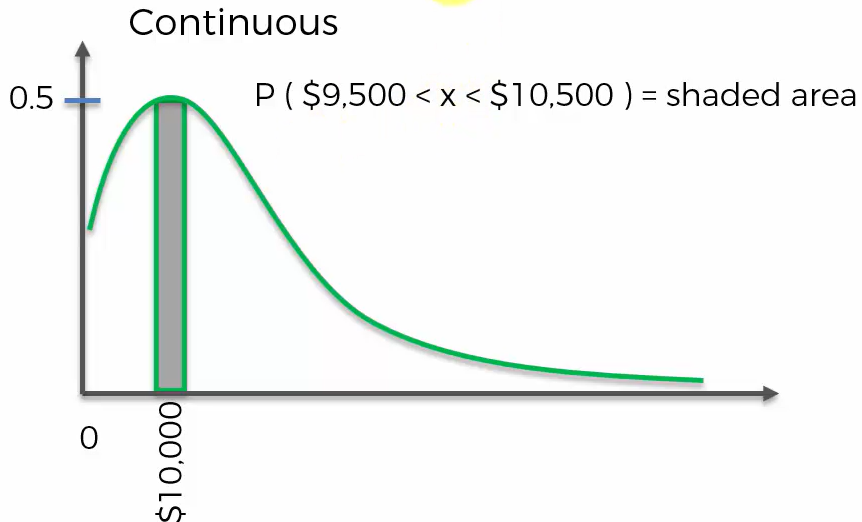
=> 특정 고객의 잔고가 정확히 만 달러일 확률은? 거의 0에 가깝다(사실상 0).
=> 특정 고객의 잔고가 9500~10500달러 사이일 확률은? 색칠된 면적의 넓이다.
=> 이렇듯, 특정 값에 대한 확률이 아닌 특정 범위에 대한 확률만을 찾을 수 있다.
이렇게 해석되기에, 아래의 곡선은 확률밀도함수PDF(Probability Density Function)라 불린다.
영역을 넓히면, 해당 영역에 데이터가 포함될 확률도 늘어날 것이다. 전체 면적은 당연히 1이다. 모든 값을 포함하기 때문이다. 그 어떤 값이라도 나올 확률은 당연히 100% 아니던가.
이해를 위한 핵심 내용은, 지난번 포스팅에서도 언급했던 것처럼 분포는 변수(=데이터)와 연관되어 있다는 것이다.
그래프가 있다고 분포가 있는 것이 아니다. 데이터 자체에 분포가 이미 들어 있다.
이를 꼭 기억하도록 하자.
'STUDY > 확률과 통계' 카테고리의 다른 글
| 비즈니스 분석 및 DS를 위한 핵심 통계학_분포 (4) 정규분포 (0) | 2024.06.14 |
|---|---|
| 비즈니스 분석 및 DS를 위한 핵심 통계학_분포 (3) 표준편차 (0) | 2024.06.14 |
| 비즈니스 분석 및 DS를 위한 핵심 통계학_분포 (1) 연속 vs 불연속 (0) | 2024.06.14 |
| [ProDS] 14. 모평균 비교에 관한 가설검정(independent two sample t-test) (0) | 2023.08.08 |
| [ProDS] 13. 모평균에 관한 가설검정(One sample t-test) (0) | 2023.08.08 |


